

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 117911区块链基础架构之数据层(上
- 114062构架设计与拆分的哲学
- 62543区块链基础架构之数据层(中
- 60684架构如何落地-----二数
- 25235架构思维之复用
- 24486架构设计-异常处理
- 22977架构如何落地-----三实
- 21858架构如何落地------四
- 17779架构如何落地------一
- 140210数据中心物理安全:不容忽视
推荐阅读
- 01-021Koin轻量级依赖注入框架,轻松
- 01-092如何用Rust架构复杂系统?
- 01-103生态系统:有哪些常有的Rust库
- 01-264面试官:RabbitMQ如何实现
- 01-155老码农眼中的数字孪生
- 01-166汽车科技迎来新纪元!奔驰、宝马、
- 01-177大型语言模型检索增强生成利器——
- 01-198GPU+生成式人工智能助力提升时
- 01-229API协议设计的十种技术
- 01-2510成本飙涨3倍,IPv4下月开始收
查电影评分上互联网?别逗了!
作者 | 汪昊
审校 | 重楼
自互联网诞生以来,互联网上的评分网站层出不穷。美国的 IMDB 和烂番茄等网站都有大量的电影评分和影评。许多人在观影之前都要上类似的网站搜索电影评分以决定自己是否要看某一部电影。可以说,在过去 10 年的人类文明发展过程中,无数的人已经养成了这一习惯。今天,我们要给大家泼一盆冷水:以后还是别上电影评分网站搜电影了。电影评分网站的评分根本就不可靠。

在说服大家之前,我们先来介绍一下什么是博尔达计数法。博尔达计数法是1770 年法国科学家提出的评选法国科学院院士的投票方法。虽然博尔达计数法的发明时间可能远远早于 1770 年,但是该方法还是以博尔达的名字命名了。博尔达计数法的投票方式如下:假设现在有 N 个候选人竞选某个职位,观众给他们投票,每个人给心中的第一名打 N 分,给第二名 N-1 分…… 最后统计所有分数的总和,得分最高的候选人获选。博尔达计数法被用在金球奖评分等活动中,时至今日仍然影响着我们。
或许我们对博尔达计数法没有那么熟悉,但我们一定见过博尔达计数法的变种——区间评分法。所谓区间评分法,举个例子,在 IMDB 上,我们看一部电影,最高分给 5 分,差一些的给 4 分,…… 这就是所谓的区间评分法。因为我们给的分数是一个区间内的整数,所以叫区间评分法。下面,我们将要告诉读者,所有基于区间评分法的评分系统都是无效评分系统。
在国际学术会议 ICHESS 2023 上,研究者发表了一篇题为 The Fallacy of Borda Count Method -- Why it is Useless with Group Intelligence and Shouldn't be Used with Big Data including Banking Customer Services 的论文,否定了大数据场景下区间评分法的合理性。因为区间评分法广泛应用于文化评分网站、电商商品和客服评价系统、银行柜员评价系统、移动通讯客服评价系统等,因此这篇论文意义深远,值得每一个人认真阅读。
这篇论文首先回顾了作者在过去 3 年发表的若干篇论文。这些论文介绍了若干零样本学习算法:ZeroMat、DotMat、RankMat、PoissonMat、PowerMat、LogitMat 等。这些论文有一个共同特点:在不借助迁移学习/元学习和预训练模型的前提下,可以不利用任何用户评分数据,极为准确的预测用户物品评分值,是人工智能历史上第一批真正意义的零样本学习算法。这些算法,可以在推荐系统领域完美的解决冷启动问题,并且效果丝毫不逊于有完整数据的非零样本学习算法。这些颠覆性的成果迫使我们重新思考整个推荐系统领域和在线评分网站评分体系的有效性。这些算法都有一个共同特点,就是充分利用了推荐系统输入数据的幂律特性,使用评分本身近似评分分布,来替代最大似然函数中的相关公式,从而达到不需要任何实际数据就能完成推荐的目的。
要想理解这些算法,就必须先理解矩阵分解算法。所谓矩阵分解算法,就是利用用户特征向量和物品特征向量的点乘来最大程度的近似用户物品评分。矩阵分解的损失函数如下:
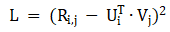
损失函数 L 可以通过随机梯度下降法进行求解。关于矩阵分解的最精确的数学解释是 2007 年的推荐系统里程碑论文 Probabilistic Matrix Factorization。这篇论文将矩阵分解重构成了最大似然函数求解问题。ZeroMat 将评分的高斯分布假设改成了真实的幂律分布,得到了如下的最大似然函数求解公式:

这个公式可以利用随机梯度下降进行求解。求解过程如下(标准差设定为 1):
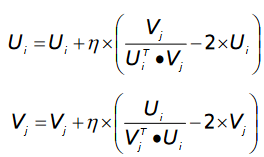
这个算法在 MovieLens 和 LDOS-CoMoDa 数据集合上进行测试,都取得了和利用全部用户评分数据进行运算的矩阵分解算法比肩的效果。
DotMat 算法的损失函数公式如下:
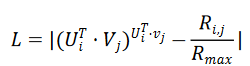
利用随机梯度下降公式对该损失函数进行求解,得到如下公式:
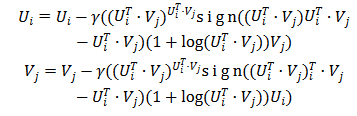
为了省略文章篇幅,下面我们只讨论 PoissonMat 和 LogitMat 这两个算法。PoissonMat 算法的最大似然函数公式如下:
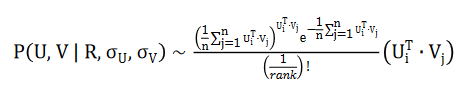
利用随机梯度下降对最大似然函数进行求解,得到如下公式:
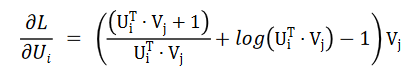
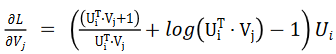
下面我们看一下 LogitMat 算法。这个算法的损失函数结合了逻辑回归和矩阵分解:
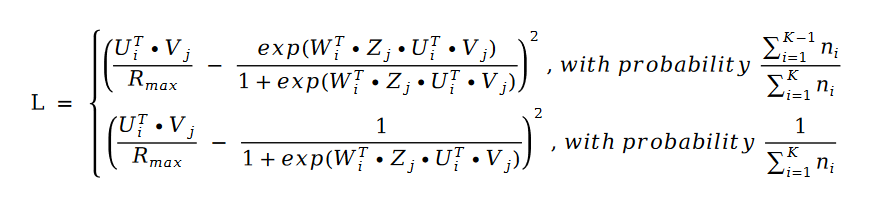
利用随机梯度下降对损失函数进行求解,得到了如下公式:
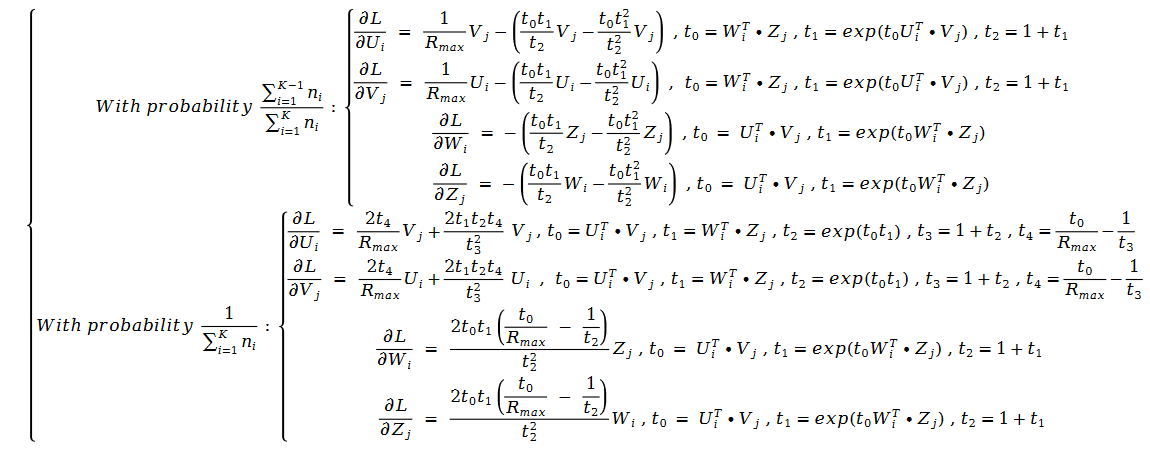
通过观察这些函数的求解公式,我们发现这些算法无一例外的都不需要任何用户评分数据。我们可以在不借助任何数据的情况下完成推荐算法的设计。下面我们从这些算法的原始论文中找出一些原始图片来分析一下算法的结果:
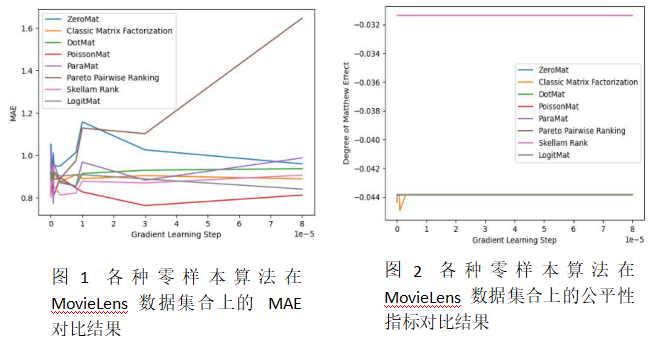
图 1 和图 2 展示的是 ZeroMat、DotMat、PoissonMat 和 LogitMat 与经典的矩阵分解模型的对比结果。可以看到,许多不需要任何数据的算法在准确性和公平性指标上都击败了经典的矩阵分解模型,而该模型利用了所有的用户评分矩阵数据。
这一系列的结果让我们有了充足的理由推翻区间评分法:因为幂律效应的原因,我们可以使用评分本身代替评分的概率分布对最大似然函数进行建模,这样可以得到零样本学习算法,并且零样本学习算法可以精确预测用户评分喜好,在 [1, 5] 评分区间上评分误差可以不超过 0.8 。这一发现在很大程度上冲击了我们对于推荐系统领域的认知。因为用户评分数据,特别是电影评分数据中的幂律效应不可避免,所以零样本算法永远成立。既然一个人给电影打多少分可以不用任何数据进行预测,这样的评分系统还有何用?因此电影评分网站的评分系统都是无效的评分系统。而这一结论可以轻易的扩展到其他区间评分的系统中去:只要该系统的输入存在幂律效应,区间评分法就是无效的。
查电影评分上互联网?别逗了!你给电影打多少分,不用查你的历史数据就能猜的很准。而这仅仅是因为电影评分的幂律效应。这样的影评评分系统,你敢用吗?
作者简介
汪昊,前 Funplus 人工智能实验室负责人。曾在 ThoughtWorks、豆瓣、百度、新浪等公司担任技术和技术高管职务。在互联网公司和金融科技、游戏等公司任职 12 年,对于人工智能、计算机图形学和区块链等领域有着深刻的见解和丰富的经验。在国际学术会议和期刊发表论文 42 篇,获得IEEE SMI 2008 最佳论文奖、ICBDT 2020 / IEEE ICISCAE 2021 / AIBT 2023 最佳论文报告奖。
关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP