

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 117911区块链基础架构之数据层(上
- 114062构架设计与拆分的哲学
- 62543区块链基础架构之数据层(中
- 60684架构如何落地-----二数
- 25235架构思维之复用
- 24486架构设计-异常处理
- 22977架构如何落地-----三实
- 21858架构如何落地------四
- 17779架构如何落地------一
- 140210数据中心物理安全:不容忽视
推荐阅读
- 01-021Koin轻量级依赖注入框架,轻松
- 01-092如何用Rust架构复杂系统?
- 01-103生态系统:有哪些常有的Rust库
- 01-264面试官:RabbitMQ如何实现
- 01-155老码农眼中的数字孪生
- 01-166汽车科技迎来新纪元!奔驰、宝马、
- 01-177大型语言模型检索增强生成利器——
- 01-198GPU+生成式人工智能助力提升时
- 01-229API协议设计的十种技术
- 01-2510成本飙涨3倍,IPv4下月开始收
尝鲜初体验:使用 Loggie 和 VictoriaLogs 快速构建新一代的日志系统

如果你熟悉Prometheus,想必你肯定也知道VictoriaMetrics,这款越来越流行的监控项目,可作为Prometheus的增强或者平替。VictoriaMetrics一个重要的亮点就是解决Prometheus在大规模Metrics指标数据量级下的存储问题。
同属于可观测性,当我们把眼光聚焦到日志领域,其实很久以来日志的一个痛点是也是存储。
当前日志存储的痛点
时下比较常见的一些开源日志存储项目有:Elasticsearch、Clickhouse、Loki等。当然,Elasticsearch和Clickhouse并非天生针对日志存储而设计,我们只是可以拿来存储日志数据而已。
比如Elasticsearch的核心是一个搜索引擎。针对日志存储的场景,可以全文检索是一大优势,但同时存在以下一些不足:
- 写入性能相对慢
- 资源占用较高
- 针对日志存储的压缩差
总体来说,Elasticsearch是一款历史悠久、被广泛使用的日志存储数据库,毕竟当年ELK的概念深入人心。但是,在当前降本增效的大背景下,很多企业还是会对Elasticsearch占用的机器资源比较敏感,如果只用于存储大量的运维类日志,性价比还是偏低。
所以前两年Grafana家的Loki横空出世,还是掀起了一点水花的,毕竟日志领域早就苦Elasticsearch久矣。
简单介绍一下Loki的优点:
- 天生就是为了存储日志设计
- 资源占用还不错
- 引入了日志流Log Stream的概念
大半年前,我们公司内部有部门开始尝试使用Loki存储一些系统日志。但总会遇到一些小问题,并不是很让人放心。除此之外,Loki的不足之处还有:
- 没有实际意义上的全文检索,所以关键字查询等可能会比较慢
- 不支持独立设置检索的label,可能导致性能等一系列问题
当然,Loki还是一个相对年轻的项目,我们可以理解这些稳定性、性能、设计上的问题可能是发展早期的阵痛。
但是,貌似很多人已经等不及了。
姗姗来迟:VictoriaLogs的优势
最近VictoriaMetrics发布了预览版的VictoriaLogs,类似Loki专门用于存储日志。鉴于VictoriaMetrics的良好名声,还是让大家对这条搅局的「鲶鱼」充满了一定的期待。
VictoriaMetrics为什么要入局搞VictoriaLogs呢?
其实从2020年的这个Issues开始:https://github.com/VictoriaMetrics/VictoriaMetrics/issues/816
VictoriaMetrics就有了研发VictoriaLogs的想法。从该issues的讨论中我们可以看出,大家对Loki还是有点微辞的,比如说存储依赖S3(本地存储不支持分布式),比如说性能。
这里节选一下issues里的吐槽:
almost 2 years passed and Loki is still unusable for scenarios with real logging data. Trying to query anything hitting more than 50k logs is exploding servers :)
不用翻译了,隔着屏幕我们都能感受到这个用户的强烈不满。
时隔两年多,VictoriaLogs终于正式来到了我们面前,那VictoriaLogs到底有哪些优势,又能解决日志存储领域的哪些问题呢?
这里我简略总结几点,感兴趣的同学可以在[官方文档]: https://docs.victoriametrics.com/VictoriaLogs/ 中寻找更多答案。
- 兼容Elasticsearch bulk接口
- 支持横向和纵向扩容
- 资源占用低
- 支持多租户
- 继承(抄)了Loki的log stream概念,但有一些优化
- 支持全文检索,提供了简单强大的LogsQL查询语法
先说VictoriaMetrics家的一大特色:兼容性。VictoriaLogs直接支持了Elasticsearch bulk API,由于市面上几乎所有的日志采集Agent都支持发送至Elasticsearch,所以可以基本做到无缝对接和迁移,无需让这些Agent都去研发增加新的输出源。(这里确实要吐槽一下Loki,连个公开的客户端Client SDK包都没有提供,这让人怎么对接呢)
但是支持横向和纵向扩容,这点由于现在VictoriaLogs预览版只提供了单节点的,暂时还无法确认。
另外在 资源占用 方面,我们可以直接看 VictoriaLogs提供的[benchmark]: https://github.com/VictoriaMetrics/VictoriaMetrics/tree/master/deployment/logs-benchmark 结果。对比Elasticsearch,从下图可以看出:
- 平均内存
- Elasticsearch:4.4 GiB
- VictoriaLogs:144 MiB
- 平均磁盘占用:
- Elasticsearch:53.9 GB
- VictoriaLogs:4.20 GB
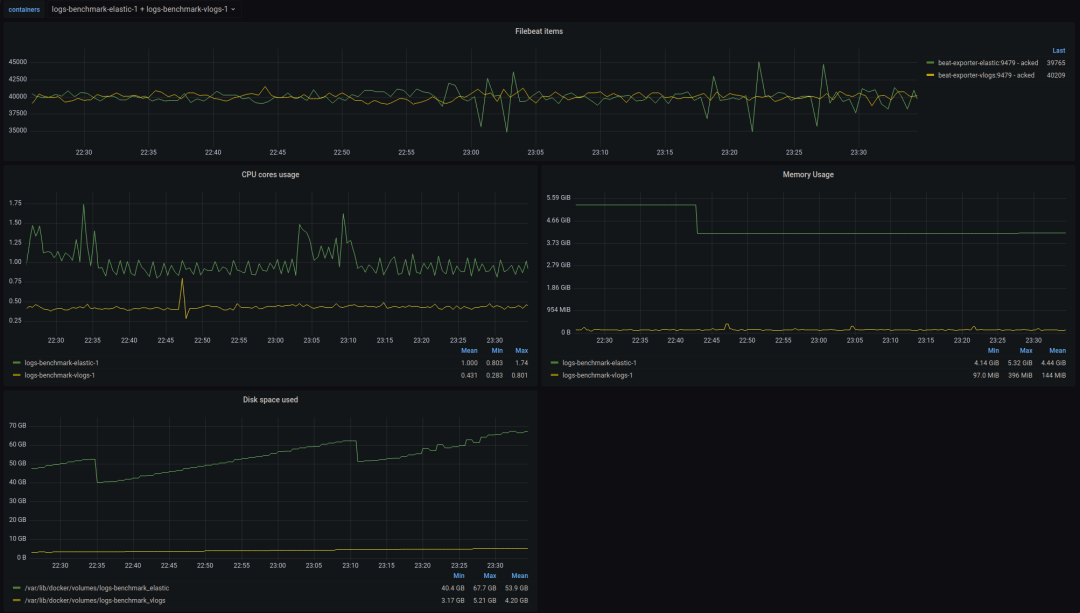
内存和磁盘占用确实要低太多,基本上是差了一个数量级,如果存储量大的话,能省下不少台服务器的钱,无疑是现在降本增效患者的一大福音。
VictoriaLogs同样引入了 log stream 的概念,结合多租户的能力,似乎可以做到日志存储场景下的性能、资源占用权衡下的最优解,这也是VictoriaLogs区别于Elasticsearch等非专门为日志存储设计数据库的核心因素。
所以在使用VictoriaLogs之前,请务必先好好了解一下log stream。
log stream是什么呢?
简单来说,表示应用(服务)的一个日志实例。至于这个日志实例的具体粒度,可以由我们自行设计和掌控,但是不建议整体数量特别大。
举例说明,一个日志实例可以为:
- 主机部署下一个Linux进程产生的日志
- Kubernetes上一个应用运行的Pod的Container容器产生的日志,或者更细粒度,容器里的一个日志文件也可以表示一个log stream
log stream设计的关键是可以被唯一标识,这样可以确定日志在分布式系统中产生的位置,比如在哪个节点的哪个容器的哪个日志文件中。
一个log stream由多个label来标识,所以其实这里和Prometheus metrics的label类似,我们可以拿Prometheus中的一些概念类比:
- job label:表示多个副本上面的应用,比如deployment名称
- instance label:表示哪个进程和端口号产生的metrics
在VictoriaLogs中也可以自己设计一些类似的label,加在日志采集的元信息中,这样还能用于后续的日志和指标的关联和检索。当然在实际的应用中,我们还可以增加诸如:环境、数据中心、namespace等的label。
如果你之前了解Loki,肯定会想说,Loki不也是这样设计label的吗?
对,但是等你深入用过Loki后,可能会遇到这样的坑:当发送的日志labels里携带了一些频繁修改的字段,比如说一条日志,将其中的偏移量offset字段作为一个label,大概如下所示:
{
"message": "xxx",
"timestamp": "",
"logconfig": "foo",
"podname": "bar",
"offset": 20,
...
}关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
上一篇:MySQL中的存储过程(详细篇)
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP