

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 117871区块链基础架构之数据层(上
- 114022构架设计与拆分的哲学
- 62503区块链基础架构之数据层(中
- 60654架构如何落地-----二数
- 25125架构思维之复用
- 24466架构设计-异常处理
- 22937架构如何落地-----三实
- 21818架构如何落地------四
- 17779架构如何落地------一
- 140010数据中心物理安全:不容忽视
推荐阅读
- 01-021Koin轻量级依赖注入框架,轻松
- 01-092如何用Rust架构复杂系统?
- 01-103生态系统:有哪些常有的Rust库
- 01-264面试官:RabbitMQ如何实现
- 01-155老码农眼中的数字孪生
- 01-166汽车科技迎来新纪元!奔驰、宝马、
- 01-177大型语言模型检索增强生成利器——
- 01-198GPU+生成式人工智能助力提升时
- 01-229API协议设计的十种技术
- 01-2510成本飙涨3倍,IPv4下月开始收
利用Apache Kafka、Flink和Druid构建实时数据架构
译者 | 陈峻
审校 | 重楼
如今,对于使用批处理工作流程的数据团队而言,要满足业务的实时要求并非易事。从数据的交付、处理到分析,整个批处理工作流往往需要大量的等待,其中包括:等待数据被发送到ETL工具处,等待数据被批量处理,等待数据被加载到数据仓库,甚至需要等待查询的完成。
不过,开源世界已对此有了解决方案:通过Apache Kafka、Flink和Druid的协同使用,我们可创建一个实时数据架构,以消除上述等待状态。如下图所示,该数据架构可以在从事件到分析、再到应用的整个数据工作流程中,无缝地提供数据的新鲜度、扩展性和可靠性。

目前,Lyft、Pinterest、Reddit和Paytm等知名公司,都在同时使用这三种由互补的数据流原生技术构建的应用,来共同处理各种实时用例。
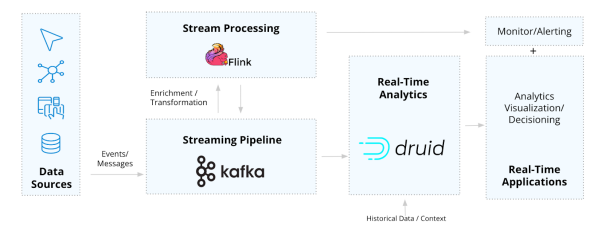 用于实时应用的开源数据架构
用于实时应用的开源数据架构
上图展现的架构能够使得构建可观察性、物联网与遥测分析、安全检测与诊断、面向客户的洞察力、以及个性化推荐等实时应用,变得简单且易于实现。下面,我们将和您探讨此类工具的各个组成部分,以及它们将如何被结合起来实现广泛的实时应用。
流管道:Apache Kafka
过去,RabbitMQ、ActiveMQ、以及其他被用来提供各种消息传递模式的消息队列系统,虽然可以将数据从生产者分发到消费者处,但是其可扩展性十分有限。而随着Apache Kafka的出现,以及被80%的财富100强企业所使用,它已成为了流式数据的实际标准。其根本原因在于,Kafka架构远不止简单的消息传递,其多功能性使之非常适合在大规模的互联网上进行数据流传输。而其容错性和数据一致性,则可以支持各类关键性任务应用。同时,由Kafka Connect提供的各种连接器,也可与任何数据源相集成。
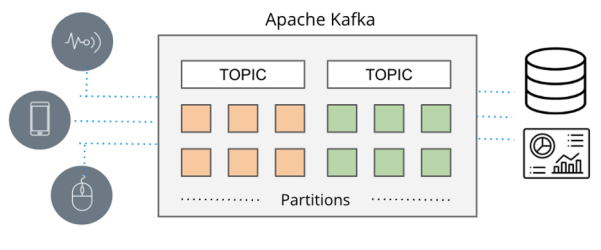 作为实时数据流平台的Apache Kafka
作为实时数据流平台的Apache Kafka
流处理:Apache Flink
Kafka虽然能够提供实时数据,但是用户在需要兼顾实时效率和扩展性时,往往会选择Apache Flink。作为一个高吞吐量且统一的数据流批处理引擎,Flink的独特优势在于能够大规模处理连续的数据流。而作为Kafka的流处理器,Flink可以无缝地集成并支持精确的一次性语义(exactly-once semantics)。也就是说,即使在系统出现故障时,它也能保证每个事件被精确地处理一次。
具体而言,它会连接到Kafka主题,定义查询逻辑,然后连续输出结果,正所谓“设置好就不用管它(set it and forget it)”。这使得Flink非常适用于对数据流的即时处理和可靠性要求较高的应用案例。以下是Flink的两个常见用例:
填充与转换
如果数据流在使用之前需要进行诸如:修改、增强或重组数据等操作,那么Flink是对此类数据流进行操作的理想引擎。它可以通过持续处理,来保持数据的新鲜度。例如,假设我们有一个安装在智能建筑中的、温度传感器的、物联网遥测用例。其每一个被捕获的Kafka事件,都具有以下JSON结构:
{ "sensor_id":"SensorA," "temperature":22.5, "timestamp":“2023-07-10T10:00:00”}关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP