

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 117871区块链基础架构之数据层(上
- 114022构架设计与拆分的哲学
- 62503区块链基础架构之数据层(中
- 60654架构如何落地-----二数
- 25145架构思维之复用
- 24466架构设计-异常处理
- 22937架构如何落地-----三实
- 21818架构如何落地------四
- 17779架构如何落地------一
- 140010数据中心物理安全:不容忽视
推荐阅读
- 01-021Koin轻量级依赖注入框架,轻松
- 01-092如何用Rust架构复杂系统?
- 01-103生态系统:有哪些常有的Rust库
- 01-264面试官:RabbitMQ如何实现
- 01-155老码农眼中的数字孪生
- 01-166汽车科技迎来新纪元!奔驰、宝马、
- 01-177大型语言模型检索增强生成利器——
- 01-198GPU+生成式人工智能助力提升时
- 01-229API协议设计的十种技术
- 01-2510成本飙涨3倍,IPv4下月开始收
在微服务架构中的数据一致性
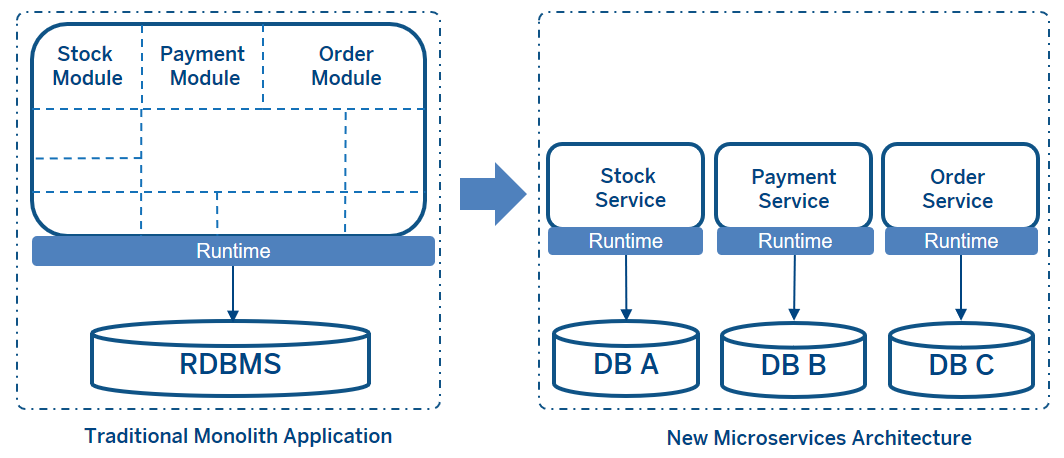
当从传统的单体应用架构转移到微服务架构时,特别是涉及数据一致性时,数据一致性是微服务架构中最困难的部分。传统的单体应用中,一个共享的关系型数据库负责处理数据一致性。在微服务架构中,如果使用“每个服务一个数据库”的模式,那么每个微服务都有自己的数据存储。
因此,数据库在应用程序之间是分布式的。如果每个应用程序使用不同的技术来管理它们的数据,比如非关系型数据库,这种分布式架构虽然在数据管理方面有许多好处,比如可伸缩性、高可用性、灵活性等,但在数据管理方面也存在一些关键问题,比如事务管理、数据一致性/完整性等方面。
问题:分布式系统中的数据一致性
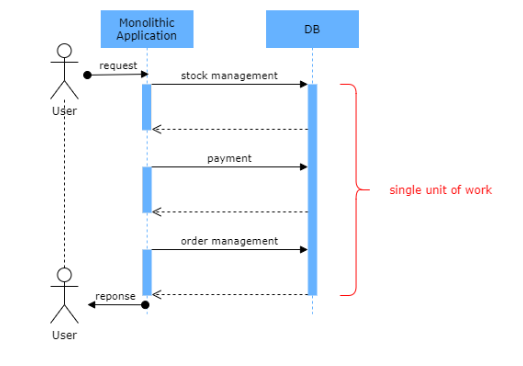
对于单体应用程序,通过ACID事务,一个共享的关系型数据库处理并保证数据的一致性。ACID 是一个缩写,具体含义如下:
- A 原子性:事务的所有步骤要么全部成功,要么全部失败,没有部分状态,全有或全无。
- C 一致性:事务结束时数据库中的所有数据都是一致的。
- I 隔离性:同一时间只有一个事务可以访问数据,其他事务必须等待当前事务完成。
- D 持久性:数据在事务结束时被持久化到数据库中。
为了保持强数据一致性,关系型数据库管理系统支持ACID特性。
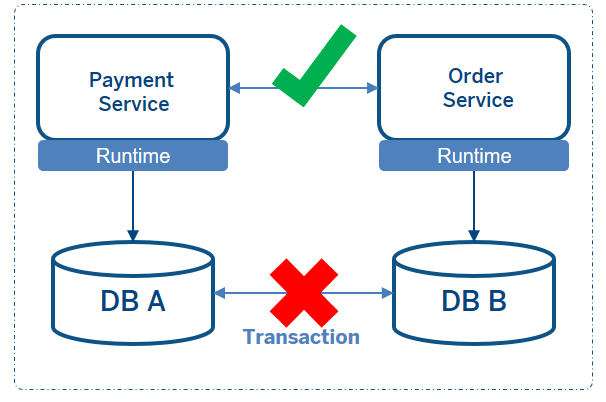
但在微服务架构中,每个微服务都有自己的数据存储,并采用不同的技术。因此,没有中央数据库,也没有单一的工作单元。业务逻辑被跨越到多个本地事务中。这意味着你不能在微服务架构中的数据库之间使用单一的事务工作单元。但你仍然需要在你的应用程序中使用ACID特性。
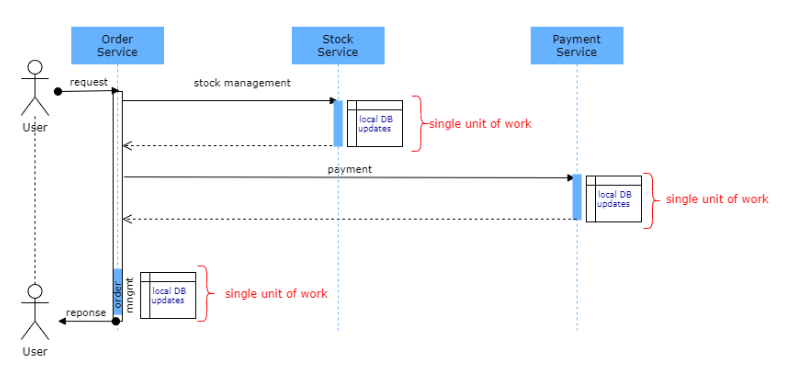
让我们用一个简单的样例场景来解释。在一个订单管理系统中,可能存在库存管理、支付和订单管理等服务。假设这些服务都按照微服务架构设计,并应用了“每个服务一个数据库”的模式。为了完成订单流程,订单服务首先调用库存管理服务进行库存控制和预留,订单中的相关产品被预留,以防止卖给其他客户。第二步是支付步骤。支付服务负责支付业务。订单服务调用支付服务,从客户的信用卡中完成支付。由于每个服务都是独立的,对分离的数据库的更新在服务范围内被提交。最后一步是创建订单记录。在这一步中,假设发生了技术错误,订单记录无法创建,订单号无法发送给客户,但已从客户那里收到了付款。这里出现了数据一致性问题。接下来我会在文章的“可能的解决方案”部分讨论在这一点之后可以做些什么。
可能的解决方案
首先,没有一种单一的解决方案适用于所有情况。根据具体情况,可以采用不同的解决方案。
解决问题有两种主要方法:
- 分布式事务
- 最终一致性
分布式事务
在分布式事务中,事务在两个或多个资源上执行(例如数据库、消息队列)。通过分布式事务管理器或协调器,跨多个数据库保证数据的完整性。
分布式事务是一个非常复杂的过程,因为涉及多个资源。
两阶段提交(2PC) 是一种阻塞协议,用于保证在分布式事务中所有事务要么全部成功,要么全部失败。
XA标准 是2PC分布式事务的规范。JTA包括Xtandard API。符合JTA标准的应用服务器支持Xtandard API。但所有资源必须部署到单个JTA平台才能运行2PC。对于微服务架构来说,这不太合适。
分布式事务的优点:
- 强的数据一致性
- 支持ACID特性
分布式事务的缺点:
- 维护起来非常复杂
- 由于是阻塞过程(不适合高负载场景),高延迟和低吞吐量
- 事务之间可能出现死锁
- 事务协调器是一个单点故障
最终一致性
最终一致性是分布式系统中用于实现高可用性的模型。在一个最终一致性的系统中,允许一段时间的不一致,直到解决分布式数据的问题。
这个模型不适用于跨多个微服务的分布式ACID事务。最终一致性使用BASE数据库模型。
虽然ACID模型提供了一个一致的系统,但BASE模型提供了高可用性。
BASE这个缩写代表:
- Basically Available:通过在数据库集群的节点之间复制数据来确保数据的可用性
- Soft-state:由于缺乏强一致性,数据可能随时间变化。一致性责任委托给开发人员。
- Eventual consistency:BASE不可能立即提供一致性,但最终会提供一致性(在短时间内)。
SAGA 是一种操作最终一致性模型的常见模式:
(1) 基于协同的SAGA:在这种情况下,不存在中央协调器。每个服务在其任务完成后产生一个事件,并且每个服务监听事件以采取行动。这种模式需要一个成熟的事件驱动架构。
- 事件溯源:使用事件存储来存储事件变化状态的方法。事件存储是充当事件数据库的消息代理。通过重新播放来自事件存储的事件来重建状态。
- 基于协同的SAGA模式在事务中步骤较少时可以很好地工作(例如2到4个步骤)。当事务中的步骤数量增加时,很难跟踪哪些服务监听哪些事件。
(2) 基于编排的SAGA:协调器服务(Saga执行编排器,SEG)负责根据业务逻辑对事务进行排序。编排器决定应执行哪些操作。如果某个操作失败,编排器会撤销先前的步骤。这称为补偿操作。补偿是在系统保持一致状态时发生故障时要执行的操作。
- 当数据已被不同的事务更改时,撤销更改可能已经不可能。
- 补偿必须是幂等的,因为在重试机制中可能会被调用多次。
- 必须小心设计补偿。
有一些可用的框架可以实现Saga编排模式,例如Camunda、Apache Camel。
SAGA的优点:
- 在本地原子事务中执行非阻塞操作
- 事务之间没有死锁
- 没有单点故障
SAGA的缺点:
- 最终的数据一致性
- 没有读隔离,需要额外的努力(例如,用户可能会看到操作已完成,但在几秒钟后由于补偿事务被取消)
- 当参与服务数量增加时,调试困难
- 开发成本增加(需要实际服务开发以及补偿服务开发)
- 设计复杂
在维护分布式数据存储之间的数据一致性可能非常困难。在设计新应用程序时需要有不同的思维方式。我们可以说,数据一致性的责任从数据库转移到了应用程序级别。
选择哪种解决方案
解决方案取决于使用案例和一致性要求。总的来说,应考虑以下设计考虑因素。
(1) 尽可能避免在微服务之间使用分布式事务。使用分布式事务会带来更复杂的问题。
(2) 设计你的系统,尽可能不要求分布式一致性。为了实现这一点,识别事务边界;
- 识别必须在同一工作单元中工作的操作。对于这种类型的操作使用强一致性
- 识别可以容忍一致性方面的可能延迟的操作。对于这种类型的操作使用最终一致性
(3) 考虑使用事件驱动架构进行异步非阻塞服务调用
(4) 通过补偿和协调过程设计容错系统,以保持系统的一致性
(5) 最终一致性模式需要在设计和开发方面进行思维方式的转变
结论
微服务架构具有诸如高可用性、可伸缩性、自动化、自治团队等很多优点。为了最大程度地发挥微服务架构风格的效率,传统方法需要进行一些改变。数据和一致性管理是需要仔细设计的。
关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
上一篇:DDD四层微服务架构
下一篇:重新思考边缘负载均衡
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP