

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 117871区块链基础架构之数据层(上
- 114022构架设计与拆分的哲学
- 62503区块链基础架构之数据层(中
- 60654架构如何落地-----二数
- 25145架构思维之复用
- 24466架构设计-异常处理
- 22937架构如何落地-----三实
- 21818架构如何落地------四
- 17779架构如何落地------一
- 140010数据中心物理安全:不容忽视
推荐阅读
- 01-021Koin轻量级依赖注入框架,轻松
- 01-092如何用Rust架构复杂系统?
- 01-103生态系统:有哪些常有的Rust库
- 01-264面试官:RabbitMQ如何实现
- 01-155老码农眼中的数字孪生
- 01-166汽车科技迎来新纪元!奔驰、宝马、
- 01-177大型语言模型检索增强生成利器——
- 01-198GPU+生成式人工智能助力提升时
- 01-229API协议设计的十种技术
- 01-2510成本飙涨3倍,IPv4下月开始收
分布式进阶-链路追踪SpringCloudSleuth、Zipkin【实战篇】

一、前言
我们在使用微服务的时候,往往涉及到各个微服务之间的调用,肯定会存在深度的调用链路,如果出现BUG或者异常,就会让问题定位和处理效率非常低。有了Sleuth ,就可以帮助我们记录、跟踪应用程序中的请求和操作。通常与 Zipkin 配合使用,从而提供更全面的可视化应用程序跟踪和分析功能。
就像ElasticSearch和Kibana一样!
复杂的链路调用如下图所示:
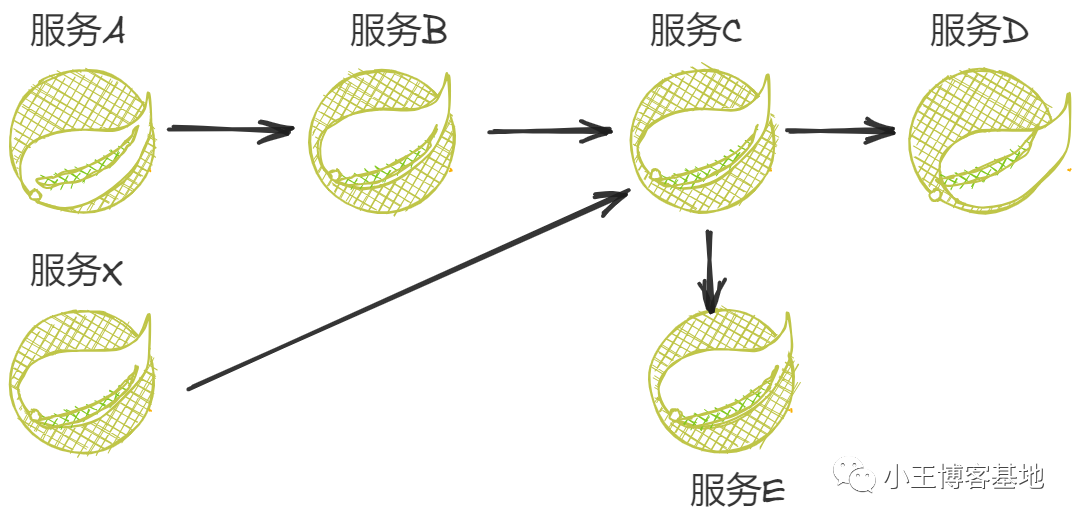
在继续往下看的同时,需要你具备Springboot整合Nacos构建一个聚合项目的能力。
当然如果不想自己来,小编也给大家准备好了。大家可以下载运行一下,开始下面的实战!
防止Github访问不了,这里把代码提交到了Gitee。
cloud-sleuth-zipkin-demo代码下载地址:https://gitee.com/wang-zhenjun/cloud-sleuth-zipkin-demo
二、Spring Cloud Sleuth 介绍
1、简介
Spring Cloud Sleuth 是 Spring Cloud 生态系统的一部分,它是一个分布式追踪解决方案,用于监视微服务架构中的请求流程,并帮助开发者跟踪请求在不同微服务之间的传播路径。
Sleuth主要用于解决微服务架构中的分布式系统跟踪和调试问题。
官网文档:https://docs.spring.io/spring-cloud-sleuth/docs/2.2.8.RELEASE/reference/html/。
2、核心概念
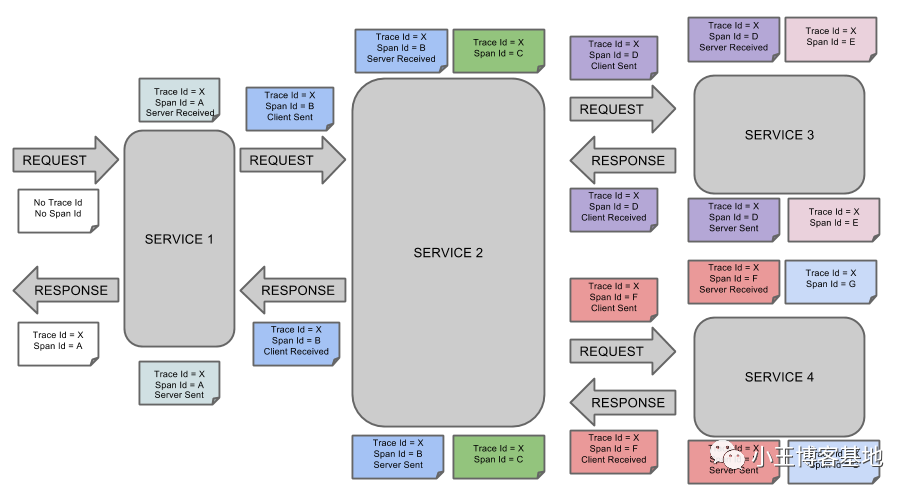
我们可以看一下官网的图片:
简单名词介绍:
?
cs:「客户端发送」,客户已提出请求。该注释指示跨度的开始。sr:「服务器已接收」,服务器端收到请求并开始处理。从此时间戳中减去cs时间戳即可得出网络延迟。ss:「服务器发送」,在请求处理完成时(当响应发送回客户端时)进行注释。从这个时间戳中减去sr时间戳就可以得出服务器端处理请求所需的时间。cr:「客户端已收到」,表示跨度的结束。客户端已成功收到服务器端的响应。从此时间戳中减去cs时间戳即可得出客户端从服务器接收响应所需的整个时间。
?
详细信息可以看官网介绍,总结一下:
名词 | 翻译 | 解释 |
Trace | 追踪 | Trace 是一个请求的整体追踪。它代表了从请求的起始点到结束点的完整路径,经过多个微服务。每个 Trace 都有一个唯一的 Trace ID。 |
Span | 跨度 | Span 是 Trace 中的一个小段,它代表了请求在某个特定微服务上的处理过程。Spans 之间有父子关系,它们可以形成一个层次结构,以表示请求的处理路径。 |
Trace ID | 追踪标识 | Trace ID 是唯一标识一个 Trace 的标识符。它在整个 Trace 中保持不变,用于将不同的 Span 关联到同一个 Trace 上。 |
Span ID | 跨度标识 | Span ID 是唯一标识一个 Span 的标识符。它用于在不同 Span 之间建立父子关系。 |
Parent Span ID | 父 Span 标识 | 父 Span ID 是标识一个 Span 的父 Span 的标识符。它用于建立 Span 之间的关系。 |
Annotations | 注解 | Annotations 是关于 Span 的额外信息,通常用于记录 Span 的开始和结束时间、操作名称、以及其他相关信息。Annotations 可以帮助你更好地理解请求的处理过程。 |
Binary Annotations | 二进制注解 | Binary Annotations 是键值对形式的信息,用于记录与 Span 相关的自定义信息,例如请求的状态、错误信息等。 |
Collector | 收集器 | Collector 是用于收集追踪信息的组件,它将追踪数据发送到后端存储或可视化工具(如Zipkin或Jaeger)。Collector 可以将 Span 数据持久化,以供分析和监视使用。 |
Sampler | 采样器 | Sampler 用于确定是否对一个请求进行追踪。它决定是否为请求创建一个 Trace。Sampler 可以根据策略决定是否记录某个请求的 Trace 数据,以避免记录过多的追踪信息,从而降低性能开销。 |
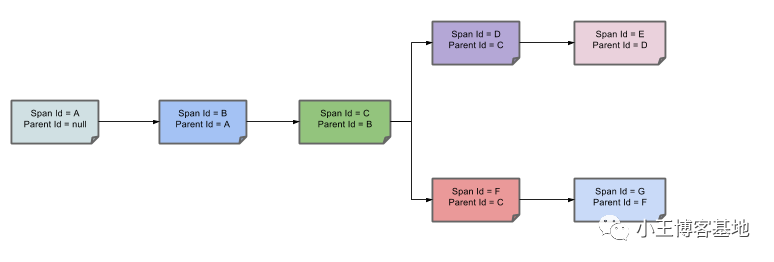
「官网的图,每一个代表一个组件,他们之间进行调用,画的少了Trace Id,加上就好了。」
每个组件都会生成一个 Trace Id(全局唯一),还会有 Span Id、Parent Id 三部分组成。链路上的所有组件组成一个完整的 Trace。
「注意:」
「头链路Parent Id = null,其余的都指向上一个组件的Span Id,从而形成链路。」
「一次链路调用所有的组件Trace Id都是一样的。」
「这里说的组件就是一个个的微服务!」
三、 Zipkin介绍和搭建
1、定义
Zipkin 是一个分布式追踪系统。它有助于收集解决服务架构中的延迟问题所需的计时数据。功能包括该数据的收集和查找。
Zipkin官网地址:https://zipkin.io/。
2、核心概念
名词 | 翻译 | 解释 |
Trace | 追踪 | Trace 代表整个请求的追踪路径,跨越不同的服务。 |
Span | 跨度 | Span 是基本工作单位,代表了请求在单个服务中的处理过程。 |
Trace ID | 追踪标识 | Trace ID 是唯一标识一个 Trace 的标识符,用于将不同的 Span 关联到同一个 Trace 上。 |
Annotations | 注解 | Annotations 用于记录 Span 的关键事件,通常包括开始和结束时间、操作名称等。 |
Binary Annotations | 二进制注解 | Binary Annotations 用于记录额外的自定义信息,例如请求状态、错误信息等。 |
Collector | 收集器 | Collector 负责接收和存储从不同服务发送的 Span 数据,以便后续的检查和分析。 |
Query and Visualization | 查询和可视化 | 提供了查询和可视化界面,允许用户查看和分析跟踪数据,以帮助故障排查和性能优化。 |
尽管Sleuth 和 Zipkin有些术语和概念中有相似之处,但它们是两个不同的工具,各自有自己的实现和用途。
「Spring Cloud Sleuth 用于生成和传播跟踪信息,而 Zipkin 用于收集、存储、查询和可视化这些信息。它们可以协同工作,但也可以独立使用。」
3、docker搭建
官方有三种方式搭建,推荐使用:「如果您熟悉 Docker,这是首选的启动方法。」
Docker Zipkin项目能够构建 docker 镜像、提供脚本和docker-compose.yml 用于启动预构建镜像的脚本。
https://github.com/openzipkin/docker-zipkin/blob/master/docker-compose.yml。
最快的启动方式是直接运行最新的镜像:
docker run -d -p 9411:9411 openzipkin/zipkin关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP