

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 117871区块链基础架构之数据层(上
- 114022构架设计与拆分的哲学
- 62503区块链基础架构之数据层(中
- 60654架构如何落地-----二数
- 25155架构思维之复用
- 24466架构设计-异常处理
- 22937架构如何落地-----三实
- 21818架构如何落地------四
- 17779架构如何落地------一
- 140010数据中心物理安全:不容忽视
推荐阅读
- 01-021Koin轻量级依赖注入框架,轻松
- 01-092如何用Rust架构复杂系统?
- 01-103生态系统:有哪些常有的Rust库
- 01-264面试官:RabbitMQ如何实现
- 01-155老码农眼中的数字孪生
- 01-166汽车科技迎来新纪元!奔驰、宝马、
- 01-177大型语言模型检索增强生成利器——
- 01-198GPU+生成式人工智能助力提升时
- 01-229API协议设计的十种技术
- 01-2510成本飙涨3倍,IPv4下月开始收
分布式实时处理系统的架构设计,工作原理和实现方式

在大数据时代,随着数据量的爆发性增长,对数据的实时处理能力提出了更高的要求。分布式实时处理系统应运而生,成为解决大规模数据实时处理的关键技术之一。本文将介绍分布式实时处理系统的架构设计,帮助您深入了解该系统的工作原理和实现方式。
架构设计
分布式实时处理系统的架构设计主要包括以下几个方面:
总体架构设计:分布式实时处理系统通常由多个节点组成,每个节点负责处理一部分数据。系统采用流模型作为计算模型,通过消息传递实现节点之间的通信。总体架构设计需要考虑节点之间的协作方式、数据流的传输方式以及容错机制等。
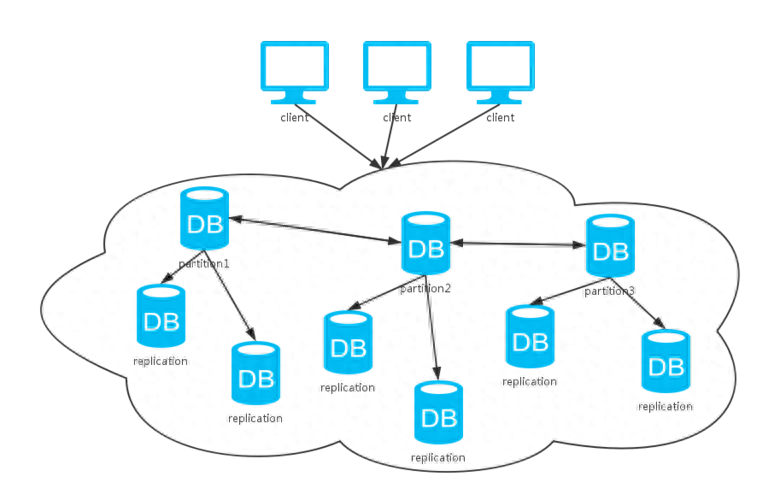
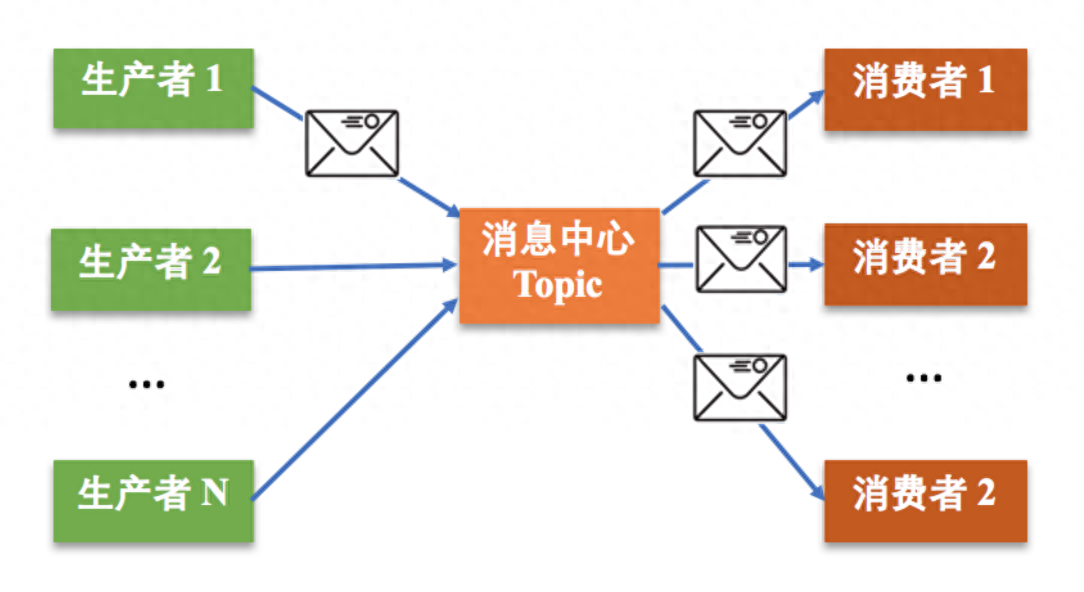
消息源和消息处理单元:消息源负责产生数据流,消息处理单元负责对数据流进行处理。消息源和消息处理单元之间通过消息队列进行通信,实现数据的传输和处理。设计合理的消息源和消息处理单元可以提高系统的性能和可扩展性。
分布式通信系统:分布式实时处理系统的节点之间需要进行高效的通信。通信系统需要支持节点之间的消息传递和数据交换,同时要具备高性能和可靠性。常用的通信方式包括RPC远程过程调用、RESTful和消息队列等。
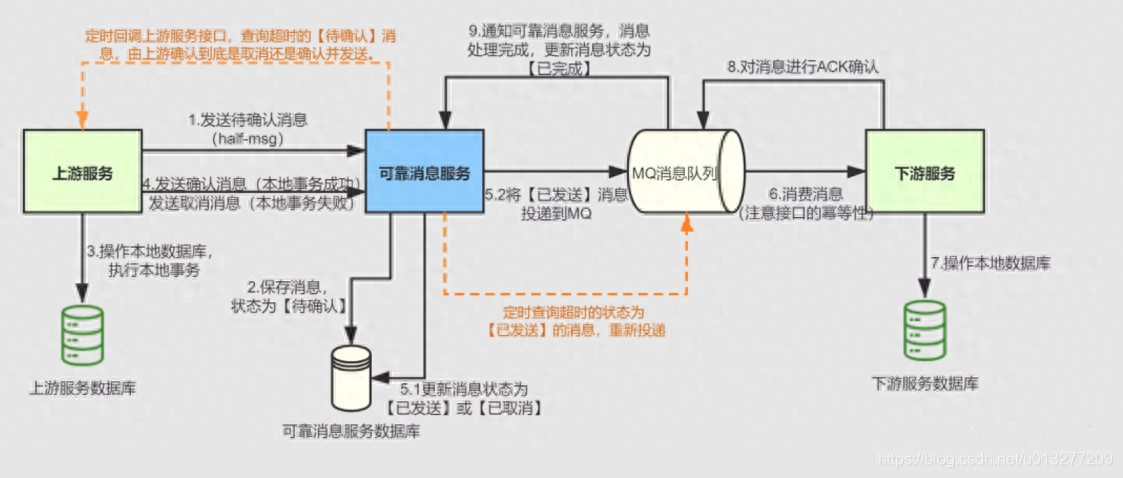
可靠消息处理:在分布式实时处理系统中,消息的可靠性是非常重要的。系统需要保证消息的传递和处理的可靠性,避免数据丢失或重复处理。可靠消息处理的设计和实现需要考虑消息的持久化、重试机制和故障恢复等。
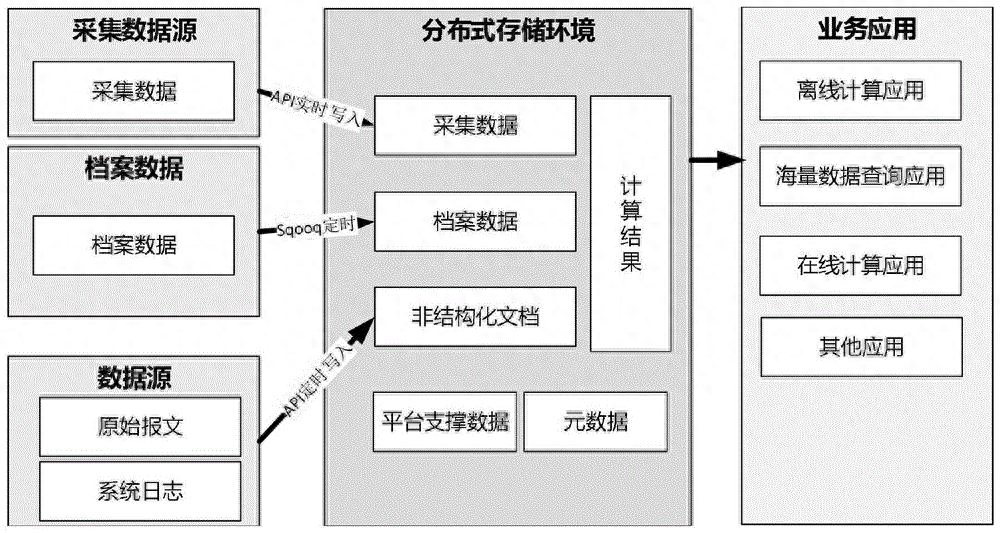
数据传输层设计:数据传输层负责实现节点之间的数据传输和通信。设计高效的数据传输层可以提高系统的性能和吞吐量。常用的数据传输层技术包括I/O多路复用和跨平台实现方案等。
高级抽象元语:高级抽象元语是分布式实时处理系统的核心组件,用于简化计算拓扑的构建和管理。通过高级抽象元语,开发人员可以更加方便地定义数据流的处理逻辑和任务分配方式。高级抽象元语的设计和实现需要考虑任务分配机制、可靠消息处理和状态存储等。
以上是分布式实时处理系统的架构设计的主要内容。通过合理的架构设计和实现,分布式实时处理系统可以实现高性能、高可靠性和可扩展性的数据处理能力,满足现代大数据应用的需求。
工作原理
分布式实时系统的工作原理是将计算任务分布到多个计算节点上,并通过实时的数据流进行通信和协调,以实现高性能和实时性的数据处理。
具体来说,分布式实时系统的工作原理包括以下几个方面:
分布式计算模型:系统需要定义一种计算模型,规定各个计算节点的运行方式、消息通信方式以及节点和数据的管理方式。
数据流处理:系统通过数据流的方式进行实时的数据处理。数据流可以是实时产生的数据,也可以是从外部数据源实时获取的数据。系统将数据流分成多个小的数据单元,通过并行处理的方式进行计算和分析。
消息传递和协调:各个计算节点之间通过消息传递进行通信和协调。节点之间可以发送消息来传递数据、状态信息和控制指令,以实现任务的分发、结果的合并和节点的同步。
资源管理:系统需要对计算节点的资源进行管理,包括内存、CPU、网络带宽等。通过合理的资源分配和调度,可以提高系统的性能和效率。
容错和可靠性:分布式实时系统需要具备容错和可靠性的特性,以应对节点故障、网络中断和数据丢失等异常情况。系统需要设计相应的机制来保证数据的完整性和一致性。
总的来说,分布式实时系统通过将计算任务分布到多个计算节点上,并通过实时的数据流进行通信和协调,实现高性能和实时性的数据处理。这种系统可以应对大规模数据处理和实时性要求较高的场景,如大数据分析、实时监控和实时推荐等。
实现方式
分布式实时系统的实现方式可以有多种,以下是几种常见的实现方式:
分布式消息队列:通过使用消息队列来实现分布式系统之间的实时通信和数据传输。消息队列可以将消息异步地发送到不同的节点,实现分布式系统的实时处理。
分布式流处理框架:通过使用流处理框架来实现分布式系统的实时处理。流处理框架可以将数据流分发到不同的节点上进行并行处理,实现实时的数据处理和分析。
分布式计算框架:通过使用分布式计算框架来实现分布式系统的实时计算。分布式计算框架可以将计算任务分发到不同的节点上进行并行计算,实现实时的数据处理和分析。
分布式数据库:通过使用分布式数据库来实现分布式系统的实时数据存储和查询。分布式数据库可以将数据分布在不同的节点上进行存储和查询,实现实时的数据访问和分析。
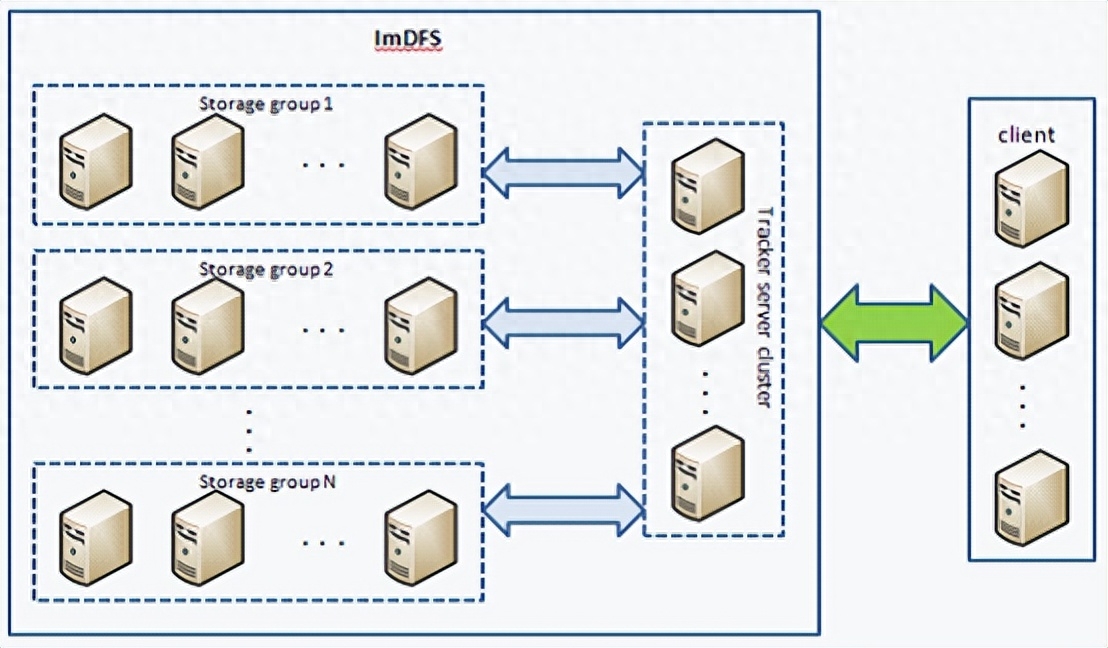
这些实现方式可以根据具体的需求和场景选择合适的技术和工具来实现分布式实时系统。
关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
下一篇:如何保证分布式情况下的幂等性
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP