

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 203581云服务器有哪些维护技巧,你
- 198732网站打开速度慢的代价:超过
- 190803域名备案需要准备什么?
- 172194云服务器小常识
- 167625云服务器和云盘的区别
- 165596个人如何注册域名?
- 165147大数据和云计算的发展前景如
- 103148MySQL体系架构
- 86819河南服务器托管哪家好?
- 509110推荐一些真正便宜的企业云服
推荐阅读
- 01-071什么是Helm?它是如何提升云原
- 01-1022024年云计算的四大趋势
- 01-123到2026年,边缘计算支出将达到
- 01-174混合云的力量实际上意味着什么?
- 01-195白话Kubernetes网络
- 01-226从集中式到分布式:云应用管理的未
- 01-237大技术时代的网络转型
- 01-248企业转型:虚拟化对云计算的影响
- 01-259到2028年,云计算市场将达到1
- 01-2510云应用管理的未来:分布式云环境
图解 Kafka 源码实现机制之客户端缓存架构设计

大家好,我是 华仔, 又跟大家见面了。
上篇主要带大家深度剖析了「Kafka 网络层收发总流程」,今天主要聊聊 「Kafka 客户端消息缓存架构设计」,深度剖析下消息是如何进行缓存的。
认真读完这篇文章,我相信你会对 Kafka 客户端缓存架构的源码有更加深刻的理解。

这篇文章干货很多,希望你可以耐心读完。
一、总体概述
通过场景驱动的方式,当被发送消息通过网络请求封装、NIO多路复用器监听网络读写事件并进行消息网络收发后,回头来看看消息是如何在客户端缓存的?
大家都知道 Kafka 是一款超高吞吐量的消息系统,主要体现在「异步发送」、「批量发送」、「消息压缩」。
跟本篇相关的是「批量发送」即生产者会将消息缓存起来,等满足一定条件后,Sender 子线程再把消息批量发送给 Kafka Broker。
这样好处就是「尽量减少网络请求次数,提升网络吞吐量」。
为了方便大家理解,所有的源码只保留骨干。
二、消息如何在客户端缓存的
既然是批量发送,那么消息肯定要进行缓存的,那消息被缓存在哪里呢?又是如何管理的?
通过下面简化流程图可以看出,待发送消息主要被缓存在 RecordAccumulator 里。
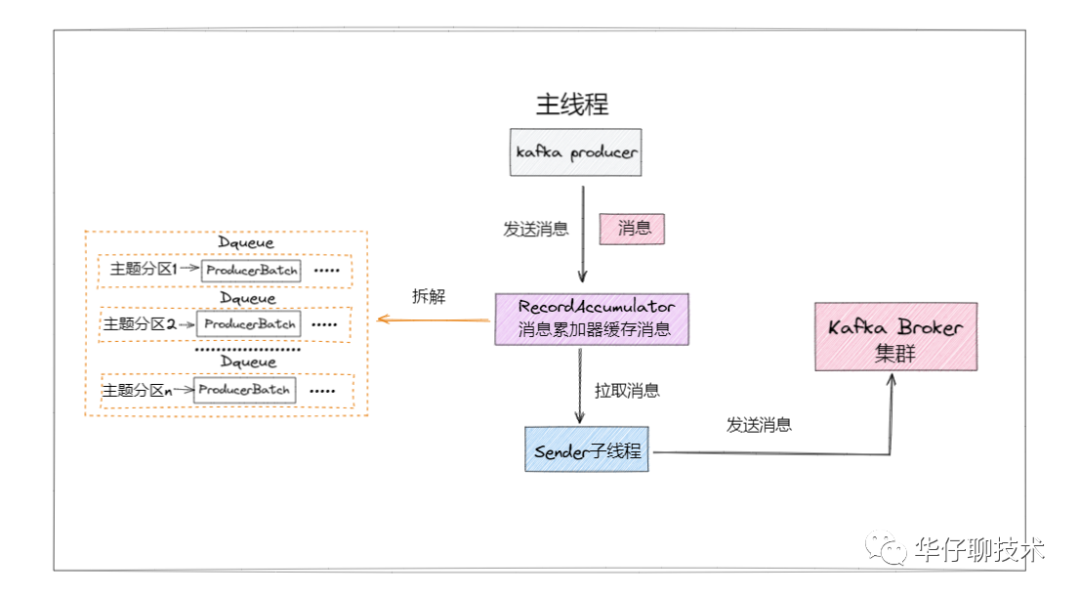
我以一个真实生活场景类比解说一下会更好理解。
既然说 RecordAccumulator 像一个累积消息的仓库,就拿快递仓库类比。

上图是一个快递仓库,堆满了货物。可以看到分拣员把不同目的地的包裹放入对应目的地的货箱,每装满一箱就放置在对应的区域。
那么分拣员就是指 RecordAccumulator,而货箱以及各自所属的堆放区域,就是 RecordAccumulator 中缓存消息的地方。所有封箱的都会等待 sender 来取货发送出去。
如果你看懂了上图,就大概理解了 RecordAccumulator 的架构设计和运行逻辑。
总结下仓库里有什么:
- 分拣员
- 货物
- 目的地
- 货箱
- 堆放区域
记住这些概念,都会体现在源码里,流程如下图所示:
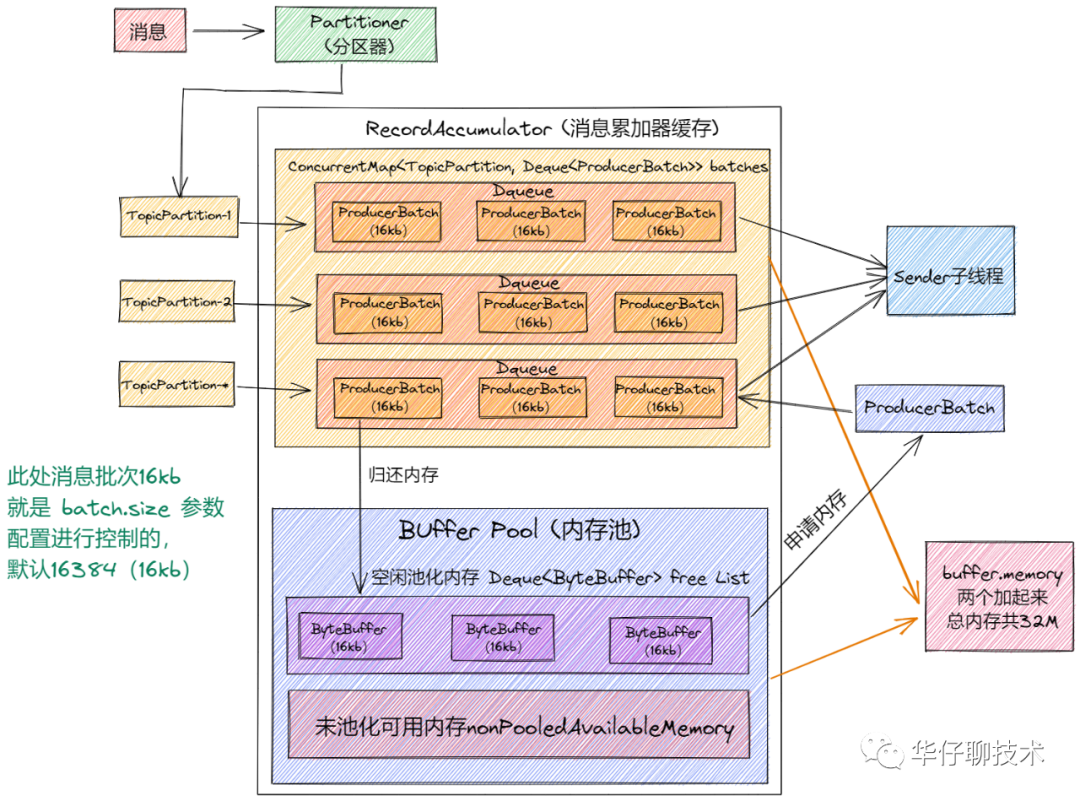
从上面图中可以看出:
- 至少有一个业务主线程和一个 sender 线程同时操作 RecordAccumulator,所以它必须是线程安全的。
- 在它里面有一个 ConcurrentMap 集合「Kafka 自定义的 CopyOnWriteMap」。key:TopicPartiton, value:Deque<ProducerBatch>,即以主题分区为单元,把消息以 ProducerBatch 为单位累积缓存,多个 ProducerBatch 保存在 Deque 队列中。当 Deque 中最新的 batch 不能容纳消息时,就会创建新的 batch 来继续缓存,并将其加入 Deque。
- 通过 ProducerBatch 进行缓存数据,为了减少频繁申请销毁内存造成 Full GC 问题,Kafka 设计了经典的「缓存池 BufferPool 机制」。
综上可以得出 RecordAccumulator 类中有三个重要的组件:「消息批次 ProducerBatch」、「自定义 CopyOnWriteMap」、「缓存池 BufferPool 机制」。
由于篇幅原因,RecordAccumulator 类放到下篇来讲解。
先来看看 ProducerBatch,它是消息缓存及发送消息的最小单位。
github 源码地址如下:
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/clients/producer/internals/ProducerBatch.java。
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/common/record/MemoryRecordsBuilder.java。
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/common/record/MemoryRecords.java。
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/common/utils/ByteBufferOutputStream.java。
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/clients/producer/internals/ProduceRequestResult.java。
https://github.com/apache/kafka/blob/2.7/clients/src/main/java/org/apache/kafka/clients/producer/internals/FutureRecordMetadata.java。

通过调用关系可以看出,ProducerBatch 依赖 MemoryRecordsBuilder,而 MemoryRecordsBuilder 依赖 MemoryRecords 构建,所以 「MemoryRecords 才是真正用来保存消息的地方」。
1、MemoryRecords
import java.nio.ByteBuffer;
public class MemoryRecords extends AbstractRecords {
public static MemoryRecordsBuilder builder(..){
// 重载builder
return builder(...);
}
public static MemoryRecordsBuilder builder(
ByteBuffer buffer,
// 消息版本
byte magic,
// 消息压缩类型
CompressionType compressionType,
// 时间戳
TimestampType timestampType,
// 基本位移
long baseOffset,
// 日志追加时间
long logAppendTime,
// 生产者id
long producerId,
// 生产者版本
short producerEpoch,
// 批次序列号
int baseSequence,
boolean isTransactional,
// 是否是控制类的批次
boolean isControlBatch,
// 分区leader的版本
int partitionLeaderEpoch) {
// 初始化MemoryRecordsBuilder类
return new MemoryRecordsBuilder(...);
}
}关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP