

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 203651云服务器有哪些维护技巧,你
- 198822网站打开速度慢的代价:超过
- 190843域名备案需要准备什么?
- 172244云服务器小常识
- 167675云服务器和云盘的区别
- 165636个人如何注册域名?
- 165167大数据和云计算的发展前景如
- 103198MySQL体系架构
- 86879河南服务器托管哪家好?
- 509610推荐一些真正便宜的企业云服
推荐阅读
- 01-071什么是Helm?它是如何提升云原
- 01-1022024年云计算的四大趋势
- 01-123到2026年,边缘计算支出将达到
- 01-174混合云的力量实际上意味着什么?
- 01-195白话Kubernetes网络
- 01-226从集中式到分布式:云应用管理的未
- 01-237大技术时代的网络转型
- 01-248企业转型:虚拟化对云计算的影响
- 01-259到2028年,云计算市场将达到1
- 01-2510云应用管理的未来:分布式云环境
自建ES集群迁移上云全攻略

业务上云过程中,势必会涉及到企业内部自建中间件等服务的迁移上云的需求,本文介绍下自建ES服务迁移上云的一些迁移方案以及如何根据业务场景选取适合的迁移方案
迁移方案
1、OSS快照
原理:以OSS为中转存储介质,使用elasticsearch-repository-oss插件关联两个集群,源集群备份数据,目标集群恢复数据(云厂商的托管ES集群默认都安装了oss插件),因为是快照模式,数据一致性得到保证,数据恢复速度也快
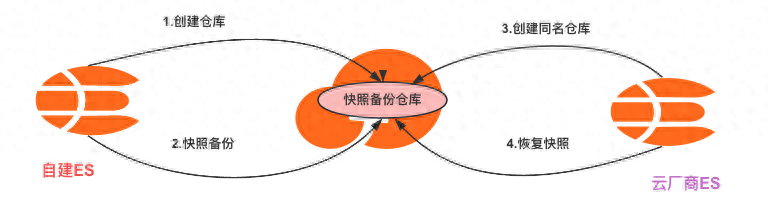
OSS迁移原理
迁移步骤拆解
源集群
- 创建OSS Bucket、设置ak、sk等信息
- 在自建集群安装安装elasticsearch-repository-oss插件,插件版本保证和集群版本一致
- 为需要迁移的索引创建快照,并将快照备份到已创建的仓库中
目标集群
- 使用snapshot API创建一个与自建Elasticsearch集群相同的快照备份仓库
- 将仓库中已备份的快照恢复到目标集群,完成数据迁移
- 快照恢复后,查看恢复的索引和索引数据
注意事项
- 这个方案的需要对原集群安装同步插件,插件有跨度过大版本兼容性问题,版本兼容性可以看插件说明文档
- 原集群备份是支持增量的,速度比较快;目标集群恢复是全量恢复,不支持增量,即目标集群每次恢复是先创建索引,在恢复数据(目标集群不能出现同名索引,否则恢复任务会失败)
- OSS备份的是主分区的数据,恢复过程也是主分区数据,副本分片的数据恢复是集群内部恢复逻辑。即:恢复任务完成时,是不包括副本数据恢复时间的。如果索引配置了写一致性,需要等副本也恢复完成才能写入成功
2、logstash
原理:logstash通俗的讲:就是一个管道,连接两端不同数据源。它的工作原理就是读取源端数据(input),经过处理(filter)发送到目标端(output),可以使用它的这个特性连接两个集群,迁移数据
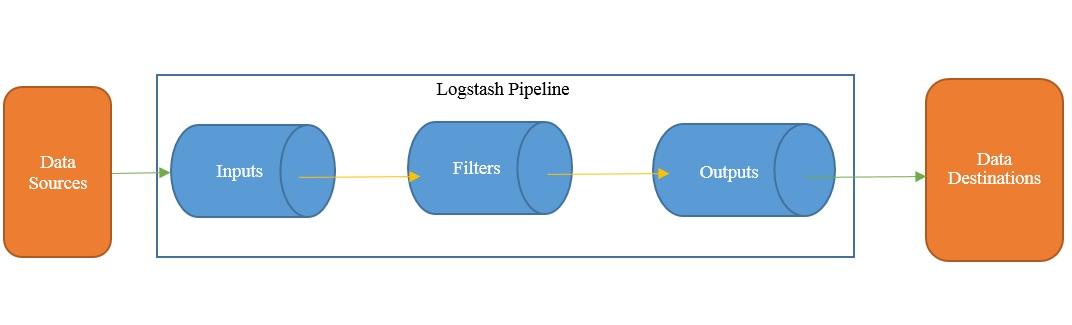
logstash工作原理
迁移步骤拆解
- 安装部署logstash
- 配置并运行logstash管道,核心配置如下
input {
elasticsearch {
hosts => ["http://<自建Elasticsearch Master节点的IP地址>:9200"]
user => "elastic"
index => "*,-.monitoring*,-.security*,-.kibana*"
password => "your_password"
docinfo => true
schedule => "*/30 * * * *" #每30分钟同步一次
}
}
filter {
}
output {
elasticsearch {
hosts => ["http:<云资源暴露的endpoint地址>//:9200"]
user => "elastic"
password => "your_password"
index => "%{[@metadata][_index]}"
document_type => "%{[@metadata][_type]}"
document_id => "%{[@metadata][_id]}"
}
}关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP