

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 158701政务云服务应突出“服务”含
- 37602政务云解决方案
- 37213电子政务应用系统发展的几个
- 11204B 站标签系统落地实践
- 11195必会的七个数据可视化库
- 10976通过数据目录集中数据治理
- 10647行业观察 | 增强分析是下
- 105982024年大数据行业预测(
- 10389四种SVM主要核函数及相关
- 1021102024年大数据展望:数据
推荐阅读
- 12-061数据科学家95%的时间都在使用的
- 12-132数据驱动业务方法
- 12-213什么是数据湖?
- 12-2642024年的14个大数据预测
- 12-295如何做销售数据分析?
- 01-0862024年大数据行业预测(一)
- 01-097如何利用数据库流服务进行实时分析
- 01-258应避免的八个数据战略错误
- 01-289第三方抢票软件不比官方快:铁路
- 01-11102024年,在云平台,开启全球外
2023年五个自动化EDA库推荐
EDA或探索性数据分析是一项耗时的工作,但是由于EDA是不可避免的,所以Python出现了很多自动化库来减少执行分析所需的时间。EDA的主要目标不是制作花哨的图形或创建彩色的图形,而是获得对数据集的理解,并获得对变量之间的分布和相关性的初步见解。我们在以前也介绍过EDA自动化的库,但是现在已经过了1年的时间了,我们看看现在有什么新的变化。
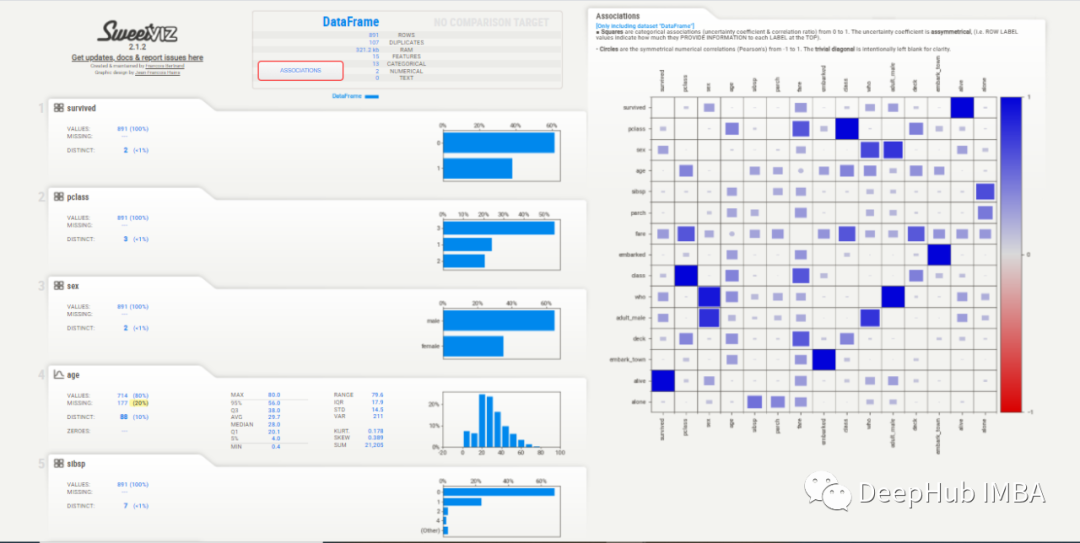
为了测试这些库的功能,本文使用了两个不同的数据集,只是为了更好地理解这些库如何处理不同类型的数据。
YData-Profiling
以前被称为Pandas Profiling,在今年改了名字。如果你搜索任何与EDA自动化相关的内容时,它都会作为第一个结果出现,这也是有充分理由的。
这个库最有用和最常用的是ProfileReport()命令。它生成整个数据集的详细摘要,报告对于获得数据的概览非常有用,特别是如果你不知道从哪里或如何开始分析(通常是这种情况)。这对于那些想要节省时间的新手或有经验的分析师来说非常有用。该报告提供单变量分布,突出数据质量问题,并创建相关性。让我们看一下患者风险概况数据的报告:
patient_data = pd.read_csv('/kaggle/input/patient-risk-profiles/patient_risk_profiles.csv')
zomato_data=pd.read_csv('/kaggle/input/zomato-data-40k-restaurants-of-indias-100-cities/zomato_dataset.csv')
from ydata_profiling import ProfileReport
patient_report=ProfileReport(patient_data)
patient_report
zomato_report=ProfileReport(zomato_data)
zomato_report关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
下一篇:经营分析,如何诊断业务问题
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP