

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 158701政务云服务应突出“服务”含
- 37602政务云解决方案
- 37213电子政务应用系统发展的几个
- 11224B 站标签系统落地实践
- 11205必会的七个数据可视化库
- 10986通过数据目录集中数据治理
- 10647行业观察 | 增强分析是下
- 106082024年大数据行业预测(
- 10389四种SVM主要核函数及相关
- 1021102024年大数据展望:数据
推荐阅读
- 12-061数据科学家95%的时间都在使用的
- 12-132数据驱动业务方法
- 12-213什么是数据湖?
- 12-2642024年的14个大数据预测
- 12-295如何做销售数据分析?
- 01-0862024年大数据行业预测(一)
- 01-097如何利用数据库流服务进行实时分析
- 01-258应避免的八个数据战略错误
- 01-289第三方抢票软件不比官方快:铁路
- 01-11102024年,在云平台,开启全球外
交互式层次聚类(RAC)算法助力大型数据集分层聚类
译者 | 朱先忠
审校 | 重楼
简介
层次聚类算法(Agglomerative Clustering)是数据科学中最好的聚类工具之一,但传统的实现无法扩展到大型数据集领域。
在这篇文章中,我将带你了解层次聚类算法的一些背景,基于谷歌2021年的研究介绍交互式层次聚类(RAC)算法、RAC++算法和Scikit Learn的层次聚类算法的运行时效果比较,最后将简要探讨一下RAC算法背后的理论支持。
层次聚类算法的背景
在数据科学领域,对未标记的数据进行聚类通常是非常有用的。从搜索引擎结果的分组到基因型分类,再到银行异常检测,聚类已经成为数据科学家们的工具包中必不可少的一部分。
层次聚类是数据科学中最流行的聚类方法之一,这是有充分的理由的:
- 易于使用,几乎不需要参数调整
- 创建有意义的分类法
- 适用于高维数据
- 不需要事先知道簇的数量
- 每次创建相同的簇
相比之下,像K-Means这样的划分方法则需要数据科学家猜测聚类的数量,非常流行的基于密度的方法DBSCAN则需要围绕密度计算半径(ε)和最小邻域大小的一些参数,而高斯混合模型对潜在的聚类数据分布做出了强有力的假设。
对于层次聚类算法,您只需要指定一个距离度量指标即可使用。
从高级视角来看,层次聚类遵循以下算法:
- 确定所有簇对之间的簇距离(每个簇从一个点开始);
- 合并彼此最接近的两个群集;
- 重复上述步骤。
结果是:生成一个美丽的树状图,然后可以根据领域专业知识进行划分应用。
在生物学和自然语言处理等领域,(细胞、基因或单词的)簇自然遵循等级关系。因此,层次聚类能够实现对最终聚类截止点的更自然和数据驱动的选择。
下图是著名的鸢尾花(Iris)数据集的层次聚类结果示例。
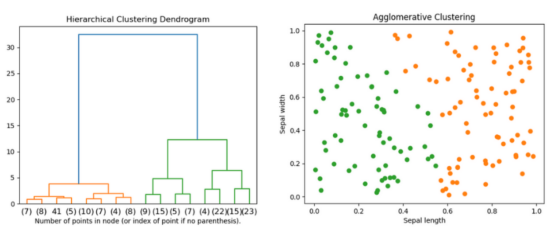
通过萼片长度和萼片宽度对著名的鸢尾花数据集进行聚类(本图表由合著作者Porter Hunley制作)
那么,为什么不对每个无监督分类问题都使用层次聚类算法呢?答案在于:
随着数据集大小的增加,层次聚类算法的运行时间表现得非常糟糕。
另一方面,不幸的是,传统的层次聚类算法还没有得到大规模的应用。如果使用最小堆结构实现的话,则运行时复杂度为O(n3)或O(n2log(n))。更糟糕的是,层次聚类算法在单核的CPU上按顺序运行,无法通过计算进行扩展。
结论是:在自然语言处理领域,层次聚类算法是小型数据集的最佳表现算法。
交互式层次聚类算法
交互式层次聚类(RAC)算法是谷歌提出的一种方法,旨在将传统型层次聚类算法的优势扩展到更大的数据集。
RAC算法降低了运行时的复杂性,同时还将操作并行化以利用多核CPU架构。尽管进行了这些优化,但当数据完全连接时,RAC产生的结果与传统的层次聚类算法却完全相同(见下文)。
注意:完全连接数据意味着,可以计算任何一对点之间的距离度量。非完全连接的数据集则具有连接约束(通常以连接矩阵的形式提供),其中一些点被认为是断开的。请参考下面的对比图示。
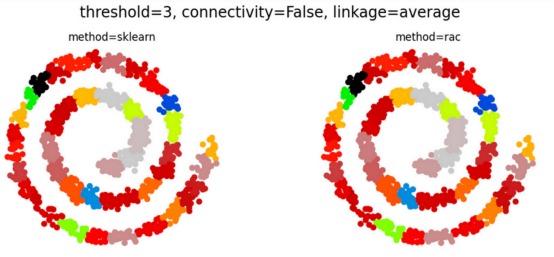

当数据完全连接时,RAC会产生与传统层次群集完全相同的结果!(上图),并且通常在连接约束的情况下继续这样做(下图)(图表由合著作者Porter Hunley制作)
即使存在连接限制(未完全连接的数据),RAC和层次聚类通常仍然相同,如上面的第二个Swiss Roll数据集示例所示。
然而,当可能的簇非常少时,可能会出现巨大的差异。这方面,Noisy Moons数据集就是一个很好的例子:


RAC算法和Sklearn算法之间的计算结果表现出不一致性(本图表由合著作者Porter Hunley制作)
RAC++算法可扩展到比Scikit-learn更大的数据集
我们可以在Scikit-learn中将RAC++算法(交互式层次聚类的一种实现)算法与其对应的层次聚类算法进行比较。
现在,不妨让我们生成一些具有25个维度的示例数据,并使用racplusplus.rac与sklearn.cluster.AglognitiveClustering测试层次聚类需要多长时间,应用于大小从1000到64000点的数据集。
注意:下面代码中,我使用连接矩阵来限制内存消耗。
import numpy as np
import racplusplus
from sklearn.cluster import AgglomerativeClustering
import time
points = [1000, 2000, 4000, 6000, 10000, 14000, 18000, 22000, 26000, 32000, 64000]
for point_no in points:
X = np.random.random((point_no, 25))
distance_threshold = .17
knn = kneighbors_graph(X, 30, include_self=False)
#矩阵必须是对称的:在Scikit-learn库的内部完成
symmetric = knn + knn.T
start = time.time()
model = AgglomerativeClustering(
linkage="average",
cnotallow=knn,
n_clusters=None,
distance_threshold=distance_threshold,
metric='cosine'
)
sklearn_times.append(time.time() - start)
start = time.time()
rac_labels = racplusplus.rac(
X, distance_threshold, symmetric,
batch_size=1000, no_cores=8, metric="cosine"
)
rac_times.append(time.time() - start)关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
上一篇:23个优秀开源免费BI仪表盘
下一篇:科技运营数据管理实践
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP