

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 158711政务云服务应突出“服务”含
- 37612政务云解决方案
- 37213电子政务应用系统发展的几个
- 11224B 站标签系统落地实践
- 11215必会的七个数据可视化库
- 10986通过数据目录集中数据治理
- 10657行业观察 | 增强分析是下
- 106082024年大数据行业预测(
- 10399四种SVM主要核函数及相关
- 1021102024年大数据展望:数据
推荐阅读
- 12-061数据科学家95%的时间都在使用的
- 12-132数据驱动业务方法
- 12-213什么是数据湖?
- 12-2642024年的14个大数据预测
- 12-295如何做销售数据分析?
- 01-0862024年大数据行业预测(一)
- 01-097如何利用数据库流服务进行实时分析
- 01-258应避免的八个数据战略错误
- 01-289第三方抢票软件不比官方快:铁路
- 01-11102024年,在云平台,开启全球外
纵腾湖仓全链路落地实践

一、总体架构
面对日益增长的数据量,Lambda 架构使用离线/实时两条链路和两种存储完成数据的保存和处理。这种繁杂的架构体系带来了不一致的问题,需要通过修数、补数等一系列监控运维手段去弥补。为了统一简化架构,提高开发效率,减少运维负担,我们实施了基于数据湖 Hudi+Flink 的流批一体架构,达到了降本增效的目的。
如下图所示,总体架构包括数据采集、ETL、查询、调度、监控、数据服务等。要解决的是数据从哪里来到哪里去,怎么过去,怎么用,以及过程中的调度和监控、元数据管理、权限管理等问题。

“数据从哪里来”,我们的数据来自 MySQL、MongoDB、Tablestore、Hana。“数据到哪里去”,我们的数据会写入到 Hudi、Doris,其中 Doris 负责存储部分应用层的数据。“数据怎么过去”,将在后面的实时入湖部分进行介绍。“数据用在哪里”,我们的数据会被 OLAP、机器学习、API、BI 查询使用,其中 OLAP 和 BI 都通过 Kyuubi 的服务进行查询。
任务的调度主要通过 DolpuinScheduler 来执行,基于 quartz 的 cronTrigger 完成 shell、SQL 等调度。监控部分则是通过 Prometheus 和 Grafana,这是业界通用的解决方案。元数据采集通过 DataHub 完成,采用了 datahub 的 ingestion framework 框架来采集各种数据源的元数据。权限管理主要包括 Kyuubi 服务端的统一认证和引擎端的独立鉴权。
二、入湖方案选型
数据入湖方案设计上,我们比较了三种入湖的实现思路。
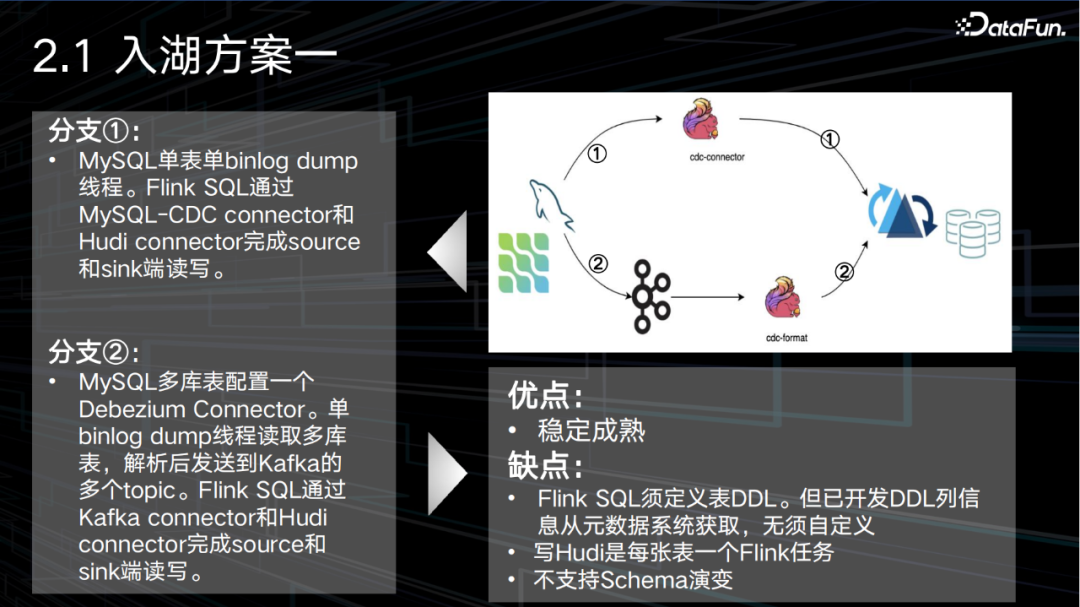
1、入湖方案一
如下图所示,包含了两条支线:
- 分支①:Flink SQL 通过 MySQL-CDC connector 和 Hudi connector 完成 source 和 sink 端读写。这样 MySQL 每张表由单独的 binlog dump 线程读取 binlog。
- 分支②:通过 MySQL 多库表配置一个 Debezium Connector 实现单独 binlog dump 线程读取多库表,解析后发送到 Kafka 的多个 topic。即一张表一个 topic。之后用 Flink SQL通过 Kafka connector 和 Hudi connector 完成 source 和 sink 端读写。
这种方案的主要优点是 Flink 和 CDC 组件都经过了充分验证,已经非常稳定成熟了。而主要缺点是 Flink SQL 需要定义表 DDL。但我们已经开发 DDL 列信息从元数据系统获取,无须自定义。并且写 Hudi 是每张表一个 Flink 任务,这样会导致资源占用过多。另外 Flink CDC 还不支持 Schema 演变,一旦 Schema 变更,需要重新拉取数据。
2、入湖方案二
这一方案是在前一个方案分支二的基础上进行了一定的改进,通过 Dinky 完成整库数据同步,其优点是同源数据合并成一个 source 节点,减轻源库压力,根据 schema、database、table 分流 sink 到对应表。其缺点是不支持 schema 演变,表结构变更须重新导数。如下图所示,mysql_biz 库中有3张表,从 flink dag 图看到 mysql cdc source 分3条流 sink 到 Hudi 的3张表。

3、入湖方案三
主要流程如下图所示。其主要优点是支持 Schema 演变。Schema 变更的信息由 Debezium 注册到 Confluence Schema Registry,schema change 的信息通过 DeltaStreamer 执行任务变更到 Hudi,使得任务执行过程中不需要重新拉起。其主要缺点是依赖于 Spark 计算引擎,而我们部门主要用 Flink,当然,这会因各个公司实际情况而不同。
下图分别是 Yarn 的 deltastreamer 任务, Kafka schema-change topic 的 DML message 和 Hudi 表变更后的数据。

4、入湖方案总结
在方案选型时,可以根据下面的流程图进行比较选择:

(1) 先看计算框架是 Spark 还是Flink,如果是Spark 则选择方案三,即 Deltastreamer,这一方案适用于表结构变更频繁,重新拉取代价高,主要技术栈是Spark 的情况。
(2) 如果是 Flink,再看数据量是否较少,以及表结构是否较稳定,如果是的话,选择方案二,Dinky 整库同步方案支持表名过滤,适用数据量较少且表结构较稳定的表。
(3) 如果否,再考虑 mysql 能否抗较大压力,如果否,那么选择方案一下分支,即 Kafka Connect,Debezium 拉取发送 Kafka,从 Kafka 读取后写 Hudi。适用数据量较大的多张表。
(4) 如果是,则选择方案一上分支,即 Flink SQL mysql-cdc 写 Hudi,适用于对实时稳定要求高于资源敏感的重要业务场景。
三、实时入湖优化
我们的入湖场景是 Flink Stream API 读取Pulsar 写 Hudi MOR 表,特点是数据量大,并且源端的每条消息都只包含了部分的列数据。我们通过使用 Hudi 的 MOR 表格式和 PartialUpdateAvroPayload 实现了这个需求。使用 Hudi 的 MOR 格式,是因为 COW 的写放大问题,不适合数据量大的实时场景,而 MOR 是增量数据写行存 Avro 格式log,通过在线或离线方式压缩合并至列存格式 parquet。在保证写效率的同时也兼顾了查询的性能。不过需要通过合并任务定期地对数据进行合并处理,这是引入复杂度的地方。
以下面这张图为例,recordKey 是 ID1 的3条 msg,每条分别包含一个列值,其余字段为空,按 ts 列 precombine,当 ts3 > ts2 > ts1时,最终 Hudi 存的 ID1 行的值是 v1,v2,v3,ts3。

此入湖场景痛点包括,MOR 表索引选择不当,压缩异常导致越写越慢,直至 checkpoint 超时,某分区存在重复文件导致写任务出错,MOR 表某个压缩计划 pending阻碍此 bucket 的压缩及后续的压缩计划生成,以及如何平衡效率与资源等。
我们在实践过程中针对一些痛点实施了相应的解决方案。
Hudi 表索引类型选择不当,导致越写越慢至 CK 超时,这是因为 Bucket 索引通过 hash 映射 recordKey 到 fileGroup。而 Bloom 索引是保存 recordKey 和 partition、fileGroup 值来实现,因此 checkpoint size 会随数据量的增加而增长。Bloom Filter 索引基于布隆过滤器实现,索引信息存储在 parquet 的 footer 中,Bloom 的假阳性问题也会导致更新越来越慢,假阳性是指只能判断数据一定不在某个文件而不能保证数据一定在某个文件,因此存在多个文件都可能存在某条数据,即须读取多个文件才能准确判断。
我们做的优化是使用 Bucket 索引代替 Bloom 索引,Hudi 目前也支持了可以动态扩容的 Bucket 参数。

MOR 表压缩执行异常,具体来说有以下三个场景:
- 单 log 超过1G,使写延迟提高,导致越写越慢至 checkpoint 超时,checkpoint 端到端耗时增长至3-6分钟。
- 在 inline schedule 的压缩模式下,offline execute 出现报错:log文件不存在。
- Compaction 一直处于 Infight 状态,即进行中,不能完成;同时存在无效 compaction,既不能被压缩,也不能被取消。
此3种现象的原因都是 Sink:compact_commit 算子的并行度 > 1,我们做的优化是降低压缩过程的并发度,设置 compact_commit Parallelism = 1。并行度改成1后1G的 log 压缩正常。整张表size 明显减少。log 到 parquet 的压缩比默认是0.35。

MOR 表某分区存在重复文件,导致写任务出错。出现这个问题的原因是某个 instant 已写 log 文件但未成功提交到 timeline 时,发生异常重启后未 rollback 这个 instant,即未清理已有 log,继续写此 instant 则有重复。
我们做的优化是在遇到重复文件时,通过 Hudi-Cli 执行去重任务,再恢复执行。具体来说,需要拆分成以下四个步骤:
- 停止当前的 Flink 任务。
- 通过 Hudi-cli 执行去重命令。
repair deduplicate --duplicatedPartitionPath 20220604 --repairedOutputPath hdfs:///hudi/hudi_tis.db/track_detail_3_repair/20220604 --dedupeType upsert_type --sparkMaster local
- 删除 partition 文件,修复文件移到原分区。
- 重新启动 Flink 任务。

MOR 表某个压缩计划 pending,阻碍此 bucket 的压缩及后续的压缩计划生成。这个问题是由于环境问题导致的 zombie compaction 或 bug。上图中第一列是compaction instant time,即压缩计划生成时间,第二列是状态,第三列是此压缩计划包含的文件数。8181的 instant 卡住,且此压缩计划包含2198个文件,即涉及到大量的 file group,涉及的 file group不会有新的压缩计划生成。导致表的 size 增加,写延时。
我们做的优化是回滚不正常的合并任务,重新处理。即利用较多资源快速离线压缩完。保证之后启动的 Flink 任务在相对少的资源情况下仍然可以保证更新和在线压缩的效率。
具体来说,包括下面的命令:
- 执行HoodieFlinkCompactor把所有inflight instant回滚成requested状态。
- 执行compaction unschedule命。
sh bin/hudi-compactor.sh hudi_tis track_detail_3 100
compaction unschedule --instant 20230613180604970 --parallelism 200 --sparkMaster local --sparkMemory 5g

经过多次的修改和验证,我们的入湖任务在性能和稳定性上取得了明显的改善。在稳定性上,做到了在十几天内任务无异常。在时延上,做到了分钟级别的 checkpoint 和数据可见。在资源使用上,对 Hadoop YARN 资源的占用明显减少。

下图总结了我们对实时入湖做的参数优化方案,包括:
- 索引选择GLOBAL_BLOOM-> BUCKET_INDEX #Bucket索引较布隆索引写吞吐性能高。
- BUCKET_NUM 20 #Bucket数量:根据单分区数据量评估,保证File Slice2GB,平衡读写性能。
Flink增量checkpoint:Rockdb #Flink ck存储,rockdb支持增量ck,减少单ck数据量,提高写吞吐。
- Yarn资源:
jobmanager 5G #Flink jobmanager内存,减少oom,保证稳定。
taskmanager 50G 20S #Flink taskmanager内存与slot数,slot与并发度、bucket数一致。
- write.rate.limit 30000 #写速度限制,过载保护,保证作业稳定运行。
- write.max.size 2560 #写用到最大内存,于taskmanager每个slot内存一致。
- write.batch.size 512 #批量写,适量调大减少刷盘频率。
- compaction.max.memory 2048 #压缩用到的最大内存,适量调大提升压缩速度。
- compaction.trigger.strategy num_and_time #压缩策略 增量提交个数或时间达标触发生成压缩策略。
- compaction.delta_seconds 30 #压缩策略之时间,减少时间间隔,减少单个压缩文件数。
- compaction.delta_commits 2 #压缩策略之增量提交个数,减少个数,减少单个压缩文件数。

实时任务入湖的优化思路流程包括下面几个步骤:
- 先确定 bucket 数量,观察 fileSlice 大小,估算调整。
- 根据 bucket 数确定 Flink job 并行度,与 bucket 数保持一致。
- 根据并行度确定 tm 资源,即并行度 = 总 slot 数。
- 根据总 slot 数确定内存,即总内存 = num(slot) * (write.max.size)。
- 根据 pulsar topic 流量确定 write.rate.limit,一般峰值 * 1.5。
- 根据 Flink job 内存使用情况及平稳度确定 write.max.size,可拿追存量数据测试,一般内存降到写速度明显下降即为内存最低值。
- 根据write.max.size 确定 write.batch.size 和 compaction.max.memory,前者是后两个的和。
- 根据 pulsar topic 流量确定压缩类型,一般超过 10w/s 考虑使用 inline schedule 和 offline execution。
四、数据湖上的查询
在引入 Kyuubi 前,我们通过 JDBC、Beeline、Spark Client、Flink Client 等客户端访问服务层执行查询,没有统一入口,多个平台不互通,多账号权限体系。用户的痛点是跨多平台开发体验差,低效率。平台层的痛点是问题定位运维复杂,存在资源浪费。
在引入 Kyuubi 后,我们基于社区版 Kyuubi 做了一定的改造,包括 JDBC 引擎开发、JDBC 引擎 Ranger 鉴权开发、BI、JDBC 客户端元数据适配修改、Spark 引擎大结果集存 HDFS、支持导数开发、JDBC 引擎 SQL 拦截控流开发等,实现了统一数据服务入口,做到了统一认证权限管理和统一易用原则。
下图展示了 Kyuubi 的架构和权限管控:

Kyuubi 查询流程是:客户端请求通过 LDAP 认证后,连接 Kyuubi Server 生成 Kyuubi session,之后 Kyuubi server 根据连接用户以及用户隔离级别路由到已经启动的 engine 或启动一个新的 engine。Spark 引擎会先申请 container 运行 AppMaster,后申请 container 运行 executor 执行 task。Flink 引擎会完成 StreamGraph 至 JobGraph 至 executionGraph 构建并通过 Jobmanager 和 taskmanager 运行。其中 engine 端 RangerPlungin 会在 SQL 解析后拉取 RangerAdmin 由用户配置的策略进行鉴权。RangerAdmin 完成用户同步,策略刷新等。
Kyuubi on Flink 跨库查询的目的是尝试基于 Flink实现流批一体,支持跨数据源导数 SQL 化。我们的实现方案是通过 Flink Metadata Catalog Connector 的开发,即基于元数据系统以统一 datasource.db.table 的格式查询所有数据源,且让用户免于自定义 DDL。其中元数据采集是用 datahub 的 ingestion framework 采集各种数据源的元数据,并生成对应 Flink 表属性。Flink 端是扩展 AbstractCatalog 查询 metadata DB,实现 CatalogFactory 接口。
其基本流程如下图所示:

完整流程是1 发起采集请求2和3是采集服务调 Datahub ingestion framework 完成元数据采集并写到 metadata DB 同时写 Flink 表属性。4是 用户发送 SQL 到 Kyuubi server 5是 Kyuubi server 发送 SQL 到 Flink engine 6和7是 Flink metadata catalog 会读取 metadata DB 根据 Flink 表属性读取对应数据源。
Kyuubi on JDBC Doris 可以通过外表查询 Hudi,但在 Doris 1.2 版本,仍然有一定的限制,Hudi 目前仅支持Copy On Write 表的 Snapshot Query,以及 Merge On Read 表的 Read Optimized Query。后续将支持 Incremental Query 和 Merge On Read 表的 Snapshot Query。
Doris 的架构示意和其基本使用流程如下图所示:

关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
下一篇:数据分析的经典方法之结构分析法
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP