

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 158671政务云服务应突出“服务”含
- 37572政务云解决方案
- 37213电子政务应用系统发展的几个
- 11204B 站标签系统落地实践
- 11115必会的七个数据可视化库
- 10926通过数据目录集中数据治理
- 10617行业观察 | 增强分析是下
- 105682024年大数据行业预测(
- 10319四种SVM主要核函数及相关
- 1018102024年大数据展望:数据
推荐阅读
- 12-061数据科学家95%的时间都在使用的
- 12-132数据驱动业务方法
- 12-213什么是数据湖?
- 12-2642024年的14个大数据预测
- 12-295如何做销售数据分析?
- 01-0862024年大数据行业预测(一)
- 01-097如何利用数据库流服务进行实时分析
- 01-258应避免的八个数据战略错误
- 01-289第三方抢票软件不比官方快:铁路
- 01-11102024年,在云平台,开启全球外
20个GitHub优秀开源大数据项目
近年来数字战略的推动进一步增加了市场对大数据相关项目的需求,而大数据技术的发展也支撑着社会数字化的发展。大数据技术的发展最开始便得益于开源社区的贡献,出现了许多优秀的大数据相关的开源项目。根据“第九届开源未来年度调查” ,全世界有72-78%的公司参与了开源项目。其中大数据35%、云计算39%、操作系统33%,物联网31%,这些技术方向的快速发展多少都离不开开源项目的推动。
下面列举了20个最受欢迎且有趣的开源大数据项目,供研究、参考。

1.Apache Beam
https://github.com/apache/beam
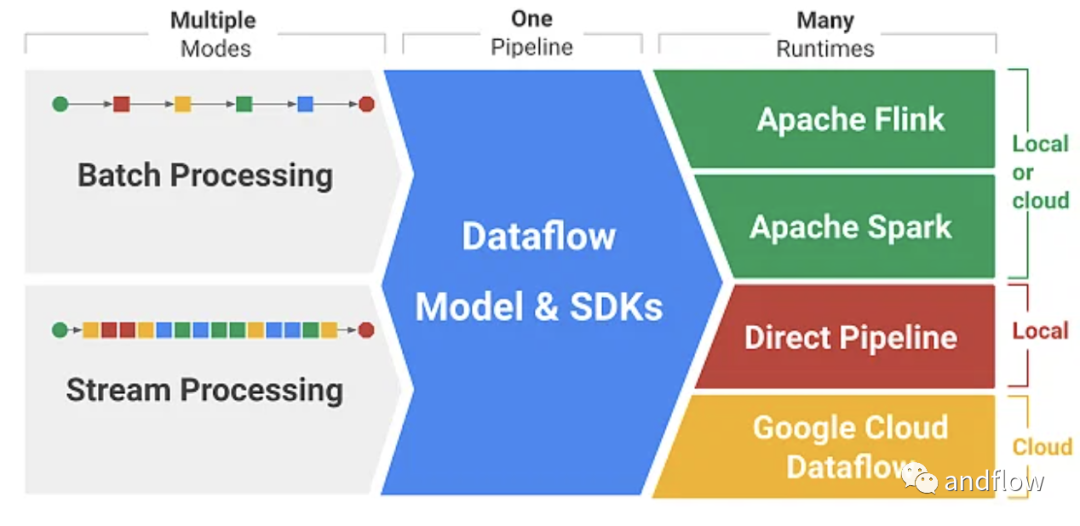
Apache Beam是2016年推出的高级统一编程开源模型。它的名字“Beam”来源于 “Batch” 和 “Stream” ,beam支持众多分布式处理后端,包括Apache Flink、Apache Spark、Apache Samza、Hazelcast Jet、Google Cloud Dataflow等。它甚至允许您使用任意三种编程语言的开源Beam SDK(软件开发工具包)构建定义数据管道的程序:Java、Python和Go。
Apache Beam 的优点主要有:统一的批处理和流式API、更高的抽象级别和跨运行时的可移植性。唯一的缺陷是透明度和可定制化较低,与其他Apache API相比,在性能优化上相对不足。
2.Clickhouse
https://github.com/ClickHouse/ClickHouse

Clickhouse是列数据库管理系统,用于在线分析处理任务(OLAP)。它允许在运行时同时创建库和表、加载数据、运行查询,无需重新配置或重新启动服务器。通过减少磁盘IO、数据本地化和压缩,clickhouse能够做到比传统关系数据库快100- 1000倍。
它的优势主要包括:使用编解码器进行数据压缩以获得出色的性能、支持多核并行处理、支持多服务器分布式处理、支持SQL语法、提供向量计算引擎、支持实时数据更新、支持自适应连接算法、支持数据复制和数据完整性、支持基于角色的访问控制等。
因为Clickhouse优秀的性能、可扩展性、可靠性和安全性。 像Yandex、CloudFare、Uber、eBay、Spotify这样的公司更倾向于使用Clickhouse。
同时Clickhouse也存在一些缺陷,例如:缺乏事务机制,没有高效的切换、删除、插入数据的能力、低延迟和稀疏索引。
3.Apache Flink
https://github.com/apache/flink

ApacheFlink是一个有状态的计算框架。它可以作为两类数据流的分布式处理引擎:无界数据流和有界数据流。Flink可以在所有典型的集群环境中运行,并在任何规模的内存中进行速度计算,支持流和批处理,具备全面的状态管理,拥有事件时(event-time)处理语义和状态的一致性保证等功能。
Flink具有动态消息、状态一致性、多语言支持、云原生、无数据库要求和“无状态”操作等优势。
Flink的常见缺点包括:社区和论坛较少、缺乏出色的API支持,以及难以对数据可视化进行编程等。
4.Nvidia RAPIDS
https://github.com/rapidsai

RAPIDS项目主要用于在GPU上运行端到端的数据科学和分析管道。基于CUDA-X AI构建,它使用NVIDIA CUDA原生语言进行基本算法优化,提供友好的Python用户界面展示GPU并行性能和高带宽内存的速度。除了分析和数据科学之外,RAPIDS还可用于日常数据预处理任务。通过提供DataFrame API,与各种机器学习算法连接,以加速端到端管道,而不会产生通常的序列化开销。RAPIDS还支持多个节点、多GPU部署,从而在更大的数据集上实现更快的处理和训练。另外,RAPIDS还具备轻松集成、顶级模型准确性、支持开源和减少学习成本等优势。
5.TDengine
https://github.com/taosdata/TDengine
TDengine是一个用于物联网、联网汽车和工业物联网的开源大数据平台。它的应用场景可以包括:机器人、电梯、 石油/天然气开采、智能家居、汽车互联网、电网、互联网接入记录、电话、金融交易以及水、空气之类的环境监测等。它集成了缓存、流计算、消息队列等功能,以降低开发的复杂性和成本,此外还附带了时间序列数据库。低云服务成本、全栈时序数据、强大的数据分析、与其他工具的无缝集成、零管理、无学习曲线是TDengine的突出亮点。
6.Apache Spark
https://github.com/apache/spark
Apache Spark是一个开源的分布式计算框架。它带有集群的编程接口,包括SQL、机器学习、实时数据流、图形处理等功能,这使其拥有快速大数据处理能力。Apache Spark的核心是Spark Core,它建立在RDD抽象之上。
Spark SQL使用DataFrames来容纳结构化和半结构化数据。Spark可以在集群模式或Hadoop YARN,EC2,Mesos,Kubernetes等环境上运行,因此可以说非常通用。
可以通过非关系型数据库访问数据,例如:Apache Cassandra、Apache HBase、Apache Hive或者Hadoop分布式文件系统等。
Apache Spark还可以根据历史或实时数据来执行实时判断,因此非常适合预测分析,欺诈检测,情感分析等应用程序。
7.Presto
https://github.com/prestodb/presto

Presto是一个开源的分布式SQL查询引擎。它使用户能够对从GB到PB的各种大小的数据源运行交互式分析查询。为交互式分析而构建是它的设计初衷,使得它可以扩展到类似Facebook的规模,同时又能够保证具备接近商业数据仓库的速度。Presto允许查询的数据库包括:Hive、Cassandra、关系数据库甚至定制数据存储等。Presto可以在一个查询中聚合来自多个数据源,支持对整个企业的数据进行分析。
但Presto在使用时也存在一些缺点,例如:它不支持大的实体连接、缺乏UDF(用户定义的函数)支持等。
8.Apache Zeppelin
https://github.com/apache/zeppelin

Apache Zeppelin是一款多用途笔记本,支持数据提取、数据发现、数据分析、数据可视化和数据协作。可以作为Apache Spark的前端Web产品,允许无缝与Spark应用程序对接。Zeppelin 解释器允许任何数据处理后端对接到Zeppelin,支持Spark、Markdown、Python、Shell和JDBC等。它提供了单用户和多用户两种部署类型。Zeppelin的最新创新包括:Zeppelin SDK,改进的Spark Interpreter,Flink Interpreter,Yarn Interpreter Mode,Inline Configuration,Interpreter Lifecycle Management。
Zeppelin也存在一些缺点,例如:UI BUG、缺乏对个别库的支持、有限的可视化配置等。
9.CMAK
https://github.com/yahoo/CMAK
CMAK是Cluster Manager for Apache Kafka的缩写,以前称为Kafka Manager,是Apache Kafka集群的管理工具。该项目目前由Verizon Media和社区共同管理。CMAK的主要功能包括:多集群管理、集群状态检查、运行首选副本选举、生成具有选择代理的选项的分区分配、运行分区重新分配(基于生成的分配)、删除主题、批量生成分区分配、批量运行多个主题的分区重新分配、添加分区或更新现有主题的配置等等。
CMAK最显著的优点是它的分区重新分配功能,但它在Ops任务的限制方面相对就是个缺点。
10.Cython
https://github.com/cython/cython

Cython是Python编程语言的静态优化器。使得为Python构建C扩展与编写Python本身一样简单。Cython结合了Python和C的强大功能,支持编写随时在原生C和C++代码之间来回切换的Python代码。
通过在Python语法中引入静态类型声明,可以快速将可理解的Python代码优化为纯C语言以提高性能。使用集成的源代码级调试,可以识别Python、Cython和C代码中存在的问题。开发人员可以在广泛且成熟的CPython生态系统中快速构建应用程序。
Cython编程语言也可以称为Python的超集,它允许在python上运行C函数并在变量和类属性上声明C类型,使编译器能够通过Cython代码构建C代码。
Cython的主要缺点包括:Cython代码不能独立重用。除此之外,通过Cython编译输出的C语言在大多数情况下都无法达到手动调优的C语言的速度。
11.CatBoost
https://github.com/catboost/catboost

CatBoost是一种机器学习决策树梯度算法。是一个开源库。它由Yandex的研究人员和工程师开发,并被Yandex和其他组织(如CERN,Cloudflare和Careem出租车)用于搜索引擎、推荐系统、个人助理、自动驾驶汽车、天气预测等应用场景。
CatBoost的功能包括:支持无需参数调整的高质量模型训练,支持分类、实现有序增强、支持GPU版本、支持缺失值、出色的可视化、高度准确性和快速预测能力。
CatBoost是解决异构数据问题的优秀解决方案,但对于处理同构数据的情况,它可能不是最好的学习器。预处理、预测时间和模型分析是Catboost的强项,而训练和优化时间则是其弱点。
12.Apache CouchDB
https://github.com/apache/couchdb

Apache CouchDB数据库于2005年由Apache Software Foundation发布。CouchDB使用Erlang开发。支持将数据存储在JSON中,使用MapReduce在JavaScript中执行查询,并通过HTTP提供API。因此,CouchDB非常适合当前的移动的应用程序。使用CouchDB的增量复制,可以高效地传输数据,CouchDB允许主——主配置与自动冲突检测。CouchDB的动态文档转换和实时更改通知等功能可以使Web开发更加简单。
CouchDB的主要缺点包括:资源消耗较大、动态查询耗时、大型数据集临时视图长耗时、缺乏事务支持、大型数据库复制的偶尔会失败。
13.Apache Airflow
https://github.com/apache/airflow

Apache Airflow是一个编程的框架,用于自动编写、调度和监控Beam数据管道。Beam数据管道是动态的,因为它们是通过编程构建的,所以我们可以使用Airflow的可视化图形或有向无环图(DAG)创建工作流任务。Airflow还提供了一个用户界面,可以轻松地实现生产中管道的可视化,便于调试问题,跟踪管道进度。它另一个优势是它的可扩展性,支持构建自己的操作符,并将库扩展到您的环境所需的抽象级别。
但是Airflow没有数据管道的版本控制,对新用户来说不太直观,开始很容易就配置过载,难以在本地使用。
14.Trino
https://github.com/trinodb/trino

Trino是一个分布式SQL查询引擎。支持从异构数据源查询大型数据集。Trino旨在解决数据仓库的联机分析处理(OLAP)问题,包括:数据分析、聚合和报告生成等。可以有效地查询分析大量数据。在Hadoop和HDFS运行环境下,Trino可以作为MapReduce功能查询HDFS,有点像Hive或Pig。Trino并不限于支持对HDFS的访问,也支持其他数据源,包括传统的关系数据库和Cassandra等。
特里诺的一个重大缺陷是,如果查询所占用的内存超过集群可用的内存,查询将失败。不过,得益于其容错能力,查询引擎将重试查询而不是直接报告失败。
15.Delta Lake
https://github.com/delta-io/delta

Delta Lake 开源项目主要用于数据湖的数据仓库设计。Delta Lake可以在现有的数据湖(如S3,ADLS,GCS和HDFS)之上,运行ACID事务、扩展的元数据处理,并且可以统一流和批处理数据。Delta Lake的主要功能包括ACID事务、可扩展的元数据处理、数据版本控制、开放的格式、统一的批处理、数据源和接收器流程化、强制执行模式、演进模式、历史审计、更新和删除、与Apache Spark API的100%兼容性和delta Sharing。
目前已经有许多公司在使用Delta Lake处理EB数据,例如:Databricks、维亚康姆、阿里巴巴集团、McAfee、Upwork、eBay、Informatica等等。
16.Apache Cassandra
https://github.com/apache/cassandra

Apache Cassandra是一个高可扩展性的数据库,可以在商业基础设施上运行,并且具有较高容错性,可以在多个节点上自动复制数据,支持在不关闭系统的情况下替换损坏的节点。Cassandra是一个NoSQL数据库,其中所有节点都是对等节点,而不是主从架构。这使得它具有高度的可扩展性和容错性,并且允许您添加更多的新机器而不中断现有应用程序。可以选择同步复制和异步复制以完成每次更新。目前像苹果、Netflix、Instagram、Spotify和Uber这些大公司都在使用Cassandra。
但Cassandra不支持ACID属性,不支持聚合、延迟、连接、数据复制、缓慢读取、VM内存管理,这些都是Apache Cassandra的缺点。
17.Vespa
https://github.com/vespa-engine/vespa

Vespa是一个用于海量数据集的低延迟计算引擎。它通过索引支持在服务时可以对其进行查询、选择和处理。通过Vespa内的应用组件,使应用程序开发人员能够构建后端以及中间件系统,这些系统可扩展以快速并可靠地处理大量数据。Vespa实例由几个无状态Java容器集群和一个或多个数据存储节点集群组成。Vespa在文本搜索、推荐、个性化、问答、半结构化导航等许多应用场合中被广泛应用。
18.Apache Calcite
https://github.com/apache/calcite

Apache Calcite是一个用于管理动态数据的全栈工具。它是一个开源的数据库和数据管理框架。它附带了一个SQL解析器、一个用于创建关系代数表达式的API和一个查询计划引擎。
尽管它包含许多标准数据库管理系统的组件,但还是缺几个关键特性,如:数据存储、数据处理方法和元数据存储库。Calcite的优点包括:查询解析器、验证器、优化器、用于阅读JSON格式模型的辅助工具、众多标准函数、聚合函数、Linq 4j的JDBC查询、JDBC后端、Linq 4j前端和SQL特性等。
19.DataHub
https://github.com/linkedin/datahub

DataHub是第三代现代数据栈的开源元数据平台,这个可扩展的元数据平台旨在帮助开发人员驾驭其快速发展的数据生态系统的复杂性,并帮助数据从业者在其组织内利用数据的最大价值。 它每天可以处理超过1000万个实体关系更改事件,并索引总计超过500万个实体和关系。与毫秒级SLA服务运营元数据查询一起完成,从而实现元数据管理具备高效率、合规性和流程化的特点。DataHub是一个现代化的数据平台,支持端到端的数据发现、数据可观察性和数据治理。
LinkedIn目前使用了DataHub来部署数据集、模式、流、合规性注释、GraphQL端点、指标、仪表板、功能和AI模型。使DataHub在实战方面经得起考验。
20.Koalas
https://github.com/databricks/koalas

Koalas项目在Apache Spark的基础上实现了pandas DataFrame API功能,使数据科学家在处理海量数据时更有效率。Spark是大数据处理的事实标准,而pandas是Python中事实标准(单节点)DataFrame实现。如果你已经熟悉了pandas,你可以立即使用Spark与Koalas,没有多少学习曲线。使用Koalas可以让用户直接与pandas一起测试较小的数据集,也可以与Spark一起测试较大的分布式数据集。
由于开源社区在几个频繁的版本中不断贡献,Koalas中pandas API的覆盖率迅速增加,并且增加了spark访问器、提升了类型提示支持、更广泛的绘图支持、更全面的就地更新支持、更好的缺失值支持等。
关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
下一篇:数据湖与实时数仓应用实践
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP