

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 158631政务云服务应突出“服务”含
- 37522政务云解决方案
- 37183电子政务应用系统发展的几个
- 11114B 站标签系统落地实践
- 11085必会的七个数据可视化库
- 10876通过数据目录集中数据治理
- 10547行业观察 | 增强分析是下
- 104982024年大数据行业预测(
- 10269四种SVM主要核函数及相关
- 1014102024年大数据展望:数据
推荐阅读
- 12-061数据科学家95%的时间都在使用的
- 12-132数据驱动业务方法
- 12-213什么是数据湖?
- 12-2642024年的14个大数据预测
- 12-295如何做销售数据分析?
- 01-0862024年大数据行业预测(一)
- 01-097如何利用数据库流服务进行实时分析
- 01-258应避免的八个数据战略错误
- 01-289第三方抢票软件不比官方快:铁路
- 01-11102024年,在云平台,开启全球外
时间序列的重采样和pandas的resample方法介绍
重采样是时间序列分析中处理时序数据的一项基本技术。它是关于将时间序列数据从一个频率转换到另一个频率,它可以更改数据的时间间隔,通过上采样增加粒度,或通过下采样减少粒度。在本文中,我们将深入研究Pandas中重新采样的关键问题。
为什么重采样很重要?
时间序列数据到达时通常带有可能与所需的分析间隔不匹配的时间戳。例如以不规则的间隔收集数据,但需要以一致的频率进行建模或分析。
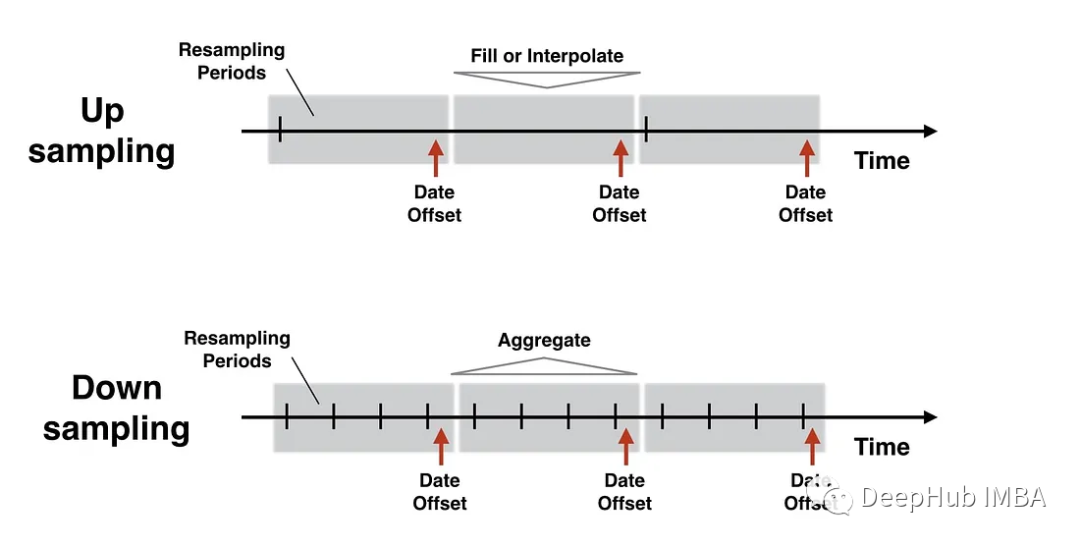
重采样分类
重采样主要有两种类型:
1、Upsampling
上采样可以增加数据的频率或粒度。这意味着将数据转换成更小的时间间隔。
2、Downsampling
下采样包括减少数据的频率或粒度。将数据转换为更大的时间间隔。
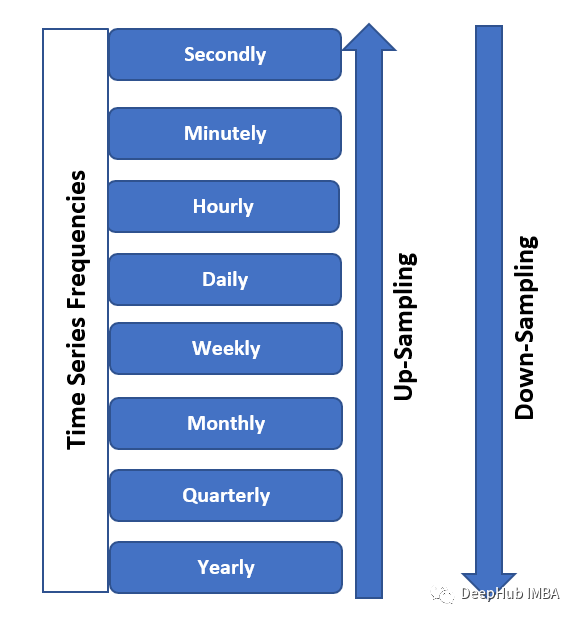
重采样的应用
重采样的应用十分广泛:
在财务分析中,股票价格或其他财务指标可能以不规则的间隔记录。重新可以将这些数据与交易策略的时间框架(如每日或每周)保持一致。
物联网(IoT)设备通常以不同的频率生成数据。重新采样可以标准化分析数据,确保一致的时间间隔。
在创建时间序列可视化时,通常需要以不同的频率显示数据。重新采样够调整绘图中的细节水平。
许多机器学习模型都需要具有一致时间间隔的数据。在为模型训练准备时间序列数据时,重采样是必不可少的。
重采样过程
重采样过程通常包括以下步骤:
首先选择要重新采样的时间序列数据。该数据可以采用各种格式,包括数值、文本或分类数据。
确定您希望重新采样数据的频率。这可以是增加粒度(上采样)或减少粒度(下采样)。
选择重新采样方法。常用的方法包括平均、求和或使用插值技术来填补数据中的空白。
在上采样时,可能会遇到原始时间戳之间缺少数据点的情况。插值方法,如线性或三次样条插值,可以用来估计这些值。
对于下采样,通常会在每个目标区间内聚合数据点。常见的聚合函数包括sum、mean或median。
评估重采样的数据,以确保它符合分析目标。检查数据的一致性、完整性和准确性。
Pandas中的resample()方法
resample可以同时操作Pandas Series和DataFrame对象。它用于执行聚合、转换或时间序列数据的下采样和上采样等操作。
下面是resample()方法的基本用法和一些常见的参数:
import pandas as pd
# 创建一个示例时间序列数据框
data = {'date': pd.date_range(start='2023-01-01', end='2023-12-31', freq='D'),
'value': range(365)}
df = pd.DataFrame(data)
# 将日期列设置为索引
df.set_index('date', inplace=True)
# 使用resample()方法进行重新采样
# 将每日数据转换为每月数据并计算每月的总和
monthly_data = df['value'].resample('M').sum()
# 将每月数据转换为每季度数据并计算每季度的平均值
quarterly_data = monthly_data.resample('Q').mean()
# 将每季度数据转换为每年数据并计算每年的最大值
annual_data = quarterly_data.resample('Y').max()
print(monthly_data)
print(quarterly_data)
print(annual_data)关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
上一篇:大数据时代,如何设计出好的指标?
下一篇:华为多模态同传翻译的落地及优化
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP