

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 141871关于域名注册需要知道的问题
- 118802浅谈融合CDN
- 61283简单网络管理协议SNMP
- 56544Multipoint BF
- 56145SBIDIOT IoT恶意
- 51376DDOS攻击的危害及防御方
- 45027企业该如何选择云服务器的配
- 41748影响云服务器价格的因素有哪
- 41429为什么选择海外云服务器?
- 311610Linux centos7
推荐阅读
- 11-061在数字化转型中,信息系统“好用”
- 11-172数字化转型的成功之道
- 12-113每个IT领导者都必须回答的八个变
- 12-184推动行业未来的八个数字化转型趋势
- 12-215初创企业和数字化转型:塑造202
- 12-256如何理性看待,中小企业数字化转型
- 01-047现代办公的数字化转型
- 01-098在什么情况下,数字化转型是成功的
- 01-159让数字化转型奏效的五大秘诀
- 01-24102024年五大数字化转型趋势
老黄祭出全新RTX 500 GPU,AIGC性能狂飙14倍!AI应用的门槛彻底被打下来了
在巴塞罗那举行的世界移动大会(MWC 2024)上,英伟达发布了最新款的入门级移动版工作站GPU,RTX 500 Ada和RTX 1000 Ada。
这两款入门级移动工作站GPU与之前发布的RTX 2000、3000、3500、4000和5000一起,构成了英伟达移动工作站GPU的整个产品线。
按照英伟达官方的说法,配备了入门级GPU的笔记本电脑,相较于使用CPU来处理AI任务的设备,效率能暴增14倍!
这两款新的GPU,将会在今年第一季度搭载在OEM的合作伙伴推出的笔记本电脑中上市。
入门级工作站移动GPU,补全产品线的最后一块拼图
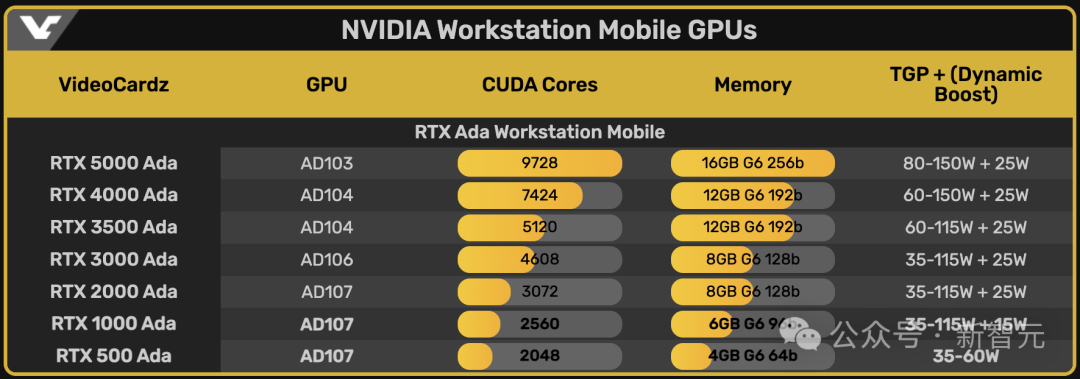
从功耗上我们就能看出来,这两款入门级的产品基本上是针对轻薄本推出的产品。
虽然配备的核心数,内存数远远低于产品线中的其他信号,但是Ada构架所支持的特性却是一点没有缩水。

- 第三代RT核心:
光线追踪性能是前代的两倍,实现了高度真实感的渲染效果。

- 第四代Tensor核心:
处理速度是上一代的两倍,加快了深度学习训练、推理过程和AI驱动的创意任务。

- Ada构架的CUDA核心:
相比前代,单精度浮点(FP32)处理能力提高了30%,在图形处理和计算任务上大幅提升了性能。

- 专用GPU内存:
RTX 500搭载了4GB内存,而RTX 1000则配备了6GB内存,足以应对复杂的3D和AI应用,处理大型项目和数据集,以及多应用并行工作流程。
- DLSS 3:
这一AI图形技术的突破性进展,通过产生更多高质量画面显著提高了性能。

- AV1编码器:
第八代编码器(NVENC)支持AV1编码,比H.264编码高效40%,为视频直播、流媒体和视频通话提供了更多可能。

基于Ampere构架的上一代产品,RTX A500和RTX A1000的的核心数都只有2048。
这一代更新后的RTX 500 Ada,保留2024个核心数不变,但是RTX 1000 Ada的核心数就提升了1/4,达到2560个,内存直接标配6GB。

而且对比上一代产品,英伟达这两个型号的GPU功率都有了不小的提升。
RTX 500从20-60W提升到了35-60W,RTX 1000从35-95W提升到了35-140W,而且RTX 1000还支持了Dynamic Boost,功耗可以再额外提升15W。
AI应用进入日常生活,入门级GPU大有可为
英伟达称,与单纯依赖CPU的配置相比,新款RTX 500 GPU能够在执行像Stable Diffusion这类模型时,提供高达14倍的AI性能。
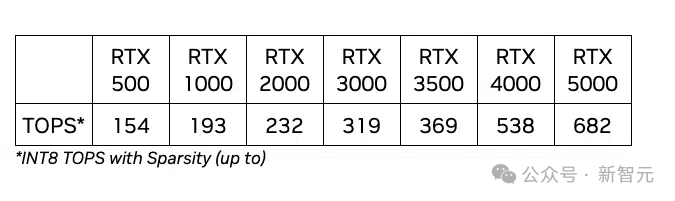
此外,AI照片编辑速度提升3倍,3D渲染的图形性能提升了10倍,将为各种工作流程带来了巨大的生产力飞跃。
随着生成式AI和混合式工作环境日益成为常态,从内容创作者到研究人员,再到工程师,几乎所有专业人士都需要一款功能强大的、支持AI加速的笔记本电脑,以便在任何地点都能有效应对行业挑战(加班)。
随着各大硬件厂商都在布局AI PC和AI手机,可以预料在不远的将来,除了专业的开发者和内容创作者之外,普通老百姓也会在日常生活中接触到大量的AI应用。

老黄在MWC如此重要的场合,抛出的却是两款最入门的移动GPU。
这似乎就是在对外宣称,在算力巨头眼里,普通的消费者也同样能够享受到技术普及带来的红利。
而传统的CPU厂家,也在今年初推出了自己带有AI能力的产品,希望从产品形态上和英伟达形成差异化竞争。

AMD第一代基于XDNA架构的神经处理单元(NPU)去年上市,作为其「Phoenix」Ryzen 7040移动处理器系列的组成部分。
其中,XDNA通过一系列特殊设计的 AI Engine 处理单元组成的网络来实现空间数据流处理。
每个AI Engine单元都配备了一个向量处理器和一个标量处理器,还有用于存储程序和数据的本地内存。
这种设计避免了传统架构中频繁从缓存中读取数据所带来的能量消耗,通过使用板载上内存和专门设计的数据流,AI Engine能够AI和信号处理任务中实现高效和低功耗的计算。
几个月后,英特尔推出了同样配备NPU的Core Ultra「Meteor Lake」构架。

英特尔的 Meteor Lake SoC将CPU,NPU,GPU结合在一起,来应对未来可能出现的不同AI应用。
Meteor Lake拥有三个功能齐全的AI引擎,Arc Xe-LPG显卡保证了AI需求的算力上限。
相比之下,NPU及其两个神经计算引擎用来承担持续的人工智能工作负载,以进一步提高能效。
CPU本身以及Redwood Cove(P)和Crestmont(E)内核的组合可以以更低的延迟处理AI工作负载,从而提高精度。
最近有消息称,微软最新推出的Windows 11 DirectML预览版将为Core Ultra NPU提供初步支持。
随着微软在操作系统层面对于AI的全面更新和支持,英特尔和AMD在CPU中加入了应对AI负载的NPU,入门级AI应用的硬件竞争必将越演越烈。

本地化运行自己的大模型,英伟达誓要将AI应用的门槛打下来
除了不断更新自己的硬件收割科技大厂,英伟达在前段时间也上线了自己第一款支持本地运行的大模型系统——Chat with RTX。

它可以让用户利用手上的消费级GPU本地化地运行开源LLM,利用用户自己的数据和知识库,定制一款专属于自己的聊天机器人。
这是英伟达推出的第一款面向普通消费者的AI应用。
简单来说,它就是英伟达自己推出的开源大模型启动器,目的是让没有技术背景的消费者能够真的在自己的设备上运行大模型。
用户想要运行Chat with RTX的要求也非常简单,只要是使用英伟达消费级的30/40系的显卡,或者Ampere/Ada GPU,拥有16G的内存,100G的空余硬盘空间,就能使用。

安装模型的时候,会自动根据显存提供支持的模型。

安装完成后,通过浏览器界面就能直接使用聊天机器人了。
而现阶段,只支持开源的Mistral 7B和 Llama2 13B。
但因为显存的关系,刚刚发布的RTX 500和1000 Ada似乎还不能运行这个系统。
但主要是因为两款支持的开源模型尺寸对于消费级GPU来说还是比较大。
如果未来英伟达能让Chat with RTX支持更多的开源模型,比如说微软前段时间推出的Phi-2 2.7B,那么即便是4G显存的RTX 500Ada也将可以本地化地跑大模型了。
关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP