

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 141871关于域名注册需要知道的问题
- 118802浅谈融合CDN
- 61283简单网络管理协议SNMP
- 56544Multipoint BF
- 56145SBIDIOT IoT恶意
- 51376DDOS攻击的危害及防御方
- 45027企业该如何选择云服务器的配
- 41748影响云服务器价格的因素有哪
- 41429为什么选择海外云服务器?
- 311610Linux centos7
推荐阅读
- 11-061在数字化转型中,信息系统“好用”
- 11-172数字化转型的成功之道
- 12-113每个IT领导者都必须回答的八个变
- 12-184推动行业未来的八个数字化转型趋势
- 12-215初创企业和数字化转型:塑造202
- 12-256如何理性看待,中小企业数字化转型
- 01-047现代办公的数字化转型
- 01-098在什么情况下,数字化转型是成功的
- 01-159让数字化转型奏效的五大秘诀
- 01-24102024年五大数字化转型趋势
谷歌10M上下文窗口正在杀死RAG?被Sora夺走风头的Gemini被低估了?
要说最近最郁闷的公司,谷歌肯定算得上一个:自家的 Gemini 1.5 刚刚发布,就被 OpenAI 的 Sora 抢尽了风头,堪称 AI 界的「汪峰」。
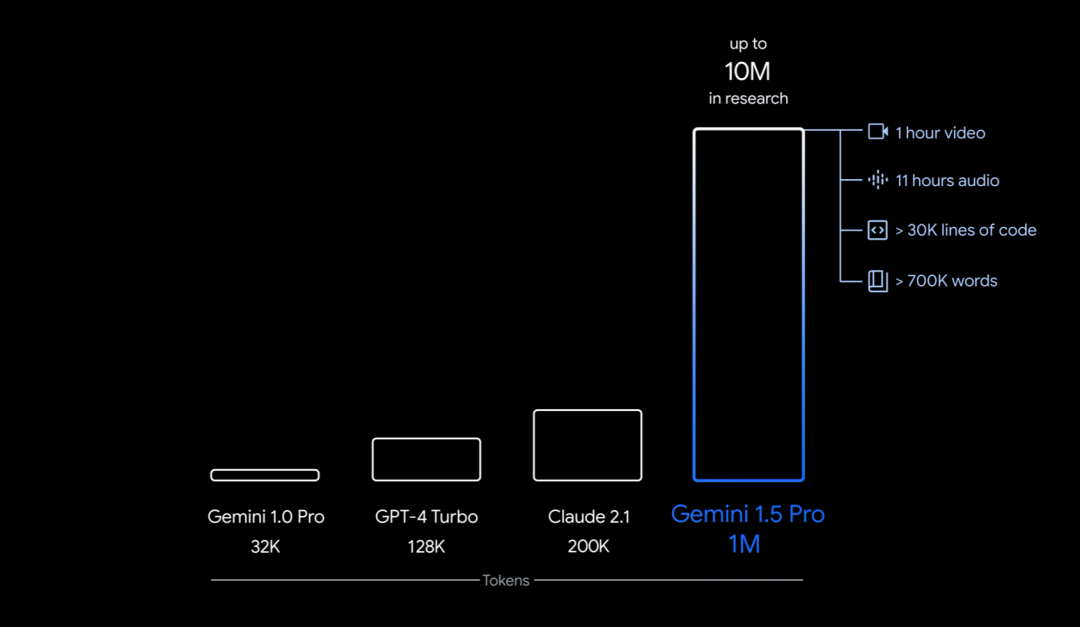
具体来说,谷歌这次推出的是用于早期测试的 Gemini 1.5 的第一个版本 ——Gemini 1.5 Pro。它是一种中型多模态模型(涉及文本、视频、音频),性能水平与谷歌迄今为止最大的模型 1.0 Ultra 类似,并引入了长上下文理解方面的突破性实验特征。它能够稳定处理高达 100 万 token(相当于 1 小时的视频、11 小时的音频、超过 3 万行代码或 70 万个单词),极限为 1000 万 token(相当于《指环王》三部曲),创下了最长上下文窗口的纪录。
此外,它还能仅靠一本 500 页的语法书、 2000 条双语词条和 400 个额外的平行句子学会一门小语种的翻译(网络上没有相关资料),翻译得分接近人类学习者。
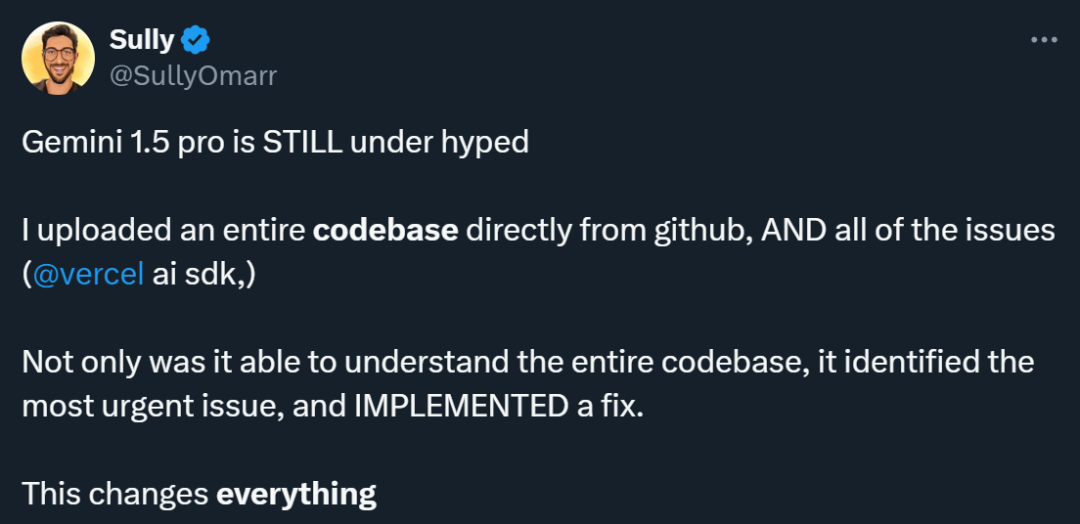
很多测试过 Gemini 1.5 Pro 的人都表示,这个模型被低估了。比如有人尝试将从 Github 上下载的整个代码库连同 issue 都扔给 Gemini 1.5 Pro,结果它不仅理解了整个代码库,还识别出了最紧急的 issue 并修复了问题。
在另一个代码相关的测试中,Gemini 1.5 Pro 也表现出了强大的检索能力(在代码库中查找出最相关的示例)、理解能力(找到控制动画的代码并给出自定义代码的建议)和跨模态的能力(凭截图找到演示并指导如何编辑图像代码)。

这样一个模型,理应引起大家的重视。而且,值得注意的是,Gemini 1.5 Pro 展现出的处理超长上下文的能力也让不少研究者开始思考,传统的 RAG 方法还有存在的必要吗?

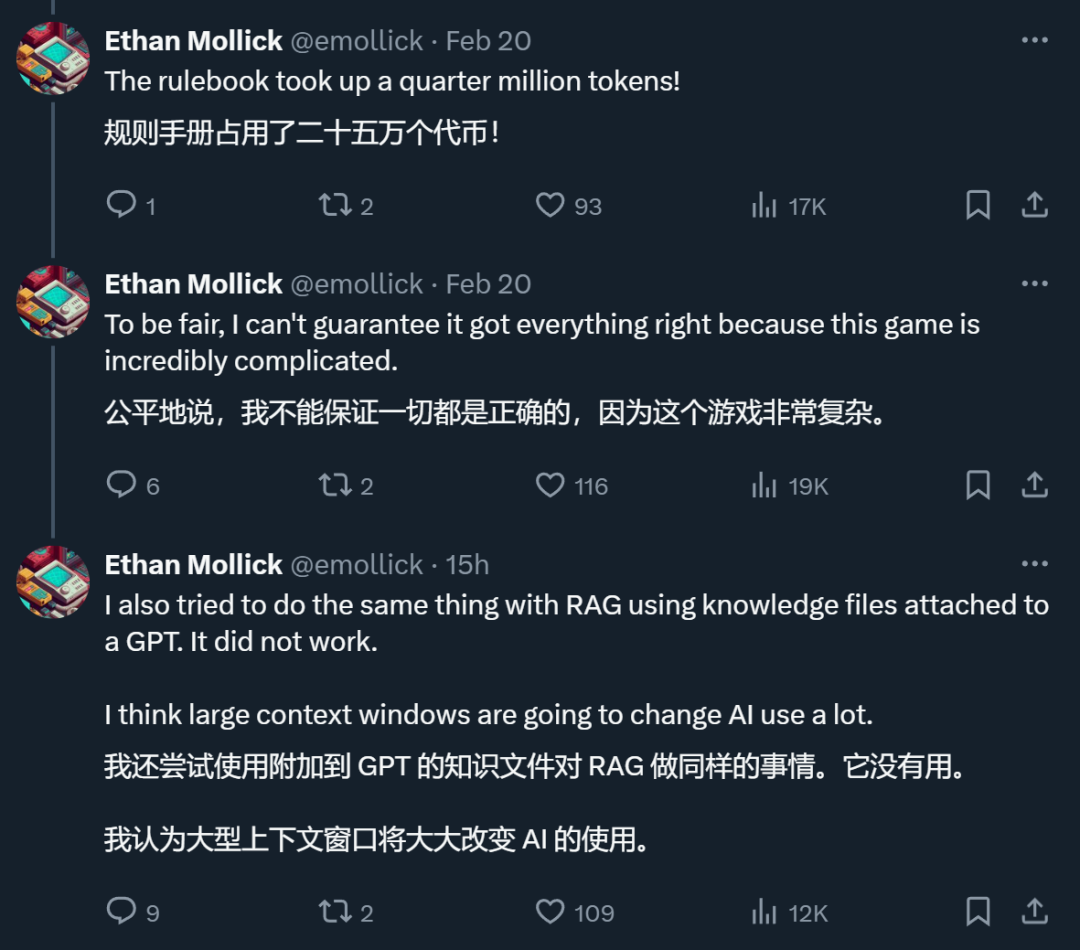
一位 X 网友表示,在他进行的一个测试中,支持超长上下文的 Gemini 1.5 Pro 确实做到了 RAG 做不到的事情。
RAG 要被长上下文模型杀死了?
「一个拥有 1000 万 token 上下文窗口的模型让大多数现有的 RAG 框架都变得不那么必要了,也就是说,1000 万 token 上下文杀死了 RAG,」爱丁堡大学博士生符尧在评价 Gemini 1.5 Pro 的帖子中写到。


RAG 是「Retrieval-Augmented Generation」的缩写,中文可以翻译为「检索增强生成」。RAG 通常包括两个阶段:检索上下文相关信息和使用检索到的知识指导生成过程。举个例子,作为一名员工,你可以直接问大模型「我们公司对迟到有什么惩罚措施?」在没有读过《员工手册》的情况下,大模型没有办法回答。但是,借助 RAG 方法,我们可以先让一个检索模型到《员工手册》里去寻找最相关的几个答案,然后把你的问题和它找到的相关答案都送到生成模型中,让大模型生成答案。这就解决了之前很多大模型上下文窗口不够大(比如容不下《员工手册》)的问题,但 RAGfangfa 在捕捉上下文之间细微联系等方面有所欠缺。
符尧认为,如果一个模型可以直接处理 1000 万 token 的上下文信息,就没有必要再通过额外的检索步骤来寻找和整合相关信息了。用户可以直接将他们需要的所有数据作为上下文放入模型中,然后像往常一样与模型进行交互。「大型语言模型本身已经是一个非常强大的检索器,为什么还要费力建立一个弱小的检索器,并在分块、嵌入、索引等方面耗费大量工程精力呢?」他继续写到。

不过,符尧的观点遭到了很多研究者的反驳。他表示,其中很多反驳都是合理的,他也将这些意见系统梳理了一下:
1、成本问题:批评者指出,RAG 比长上下文模型便宜。符尧承认这一点,但他比较了不同技术的发展历程,指出虽然低成本模型(如 BERT-small 或 n-gram)确实便宜,但在 AI 发展的历史中,先进技术的成本最终都会降低。他的观点是,首先追求智能模型的性能,然后再通过技术进步降低成本,因为让智能模型变得便宜比让便宜模型变得智能要容易得多。

2、检索与推理的整合:符尧强调,长上下文模型能够在整个解码过程中混合检索和推理,而 RAG 仅在开始时进行检索。长上下文模型可以在每一层、每一个 token 进行检索,这意味着模型能够根据初步推理的结果动态决定需要检索的信息,实现更紧密的检索与推理整合。
3、支持的 token 数量:尽管 RAG 支持的 token 数量达到了万亿级别,而长上下文模型目前支持的是百万级别,符尧认为,在自然分布的输入文档中,大多数需要检索的情况都在百万级别以下。他以法律文档分析和学习机器学习为例,认为这些情况下的输入量并不会超过百万级别。

4、缓存机制:关于长上下文模型需要重新输入整个文档的问题,符尧指出存在所谓的 KV(键值)缓存机制,可以设计复杂的缓存和内存层次结构,使得输入只需读取一次,后续查询可以重用 KV 缓存。他还提到,尽管 KV 缓存可能很大,但他对未来会出现高效的 KV 缓存压缩算法持乐观态度。
5、调用搜索引擎的需求:他承认,在短期内,调用搜索引擎进行检索仍然是必要的。然而,他提出了一个大胆的设想,即让语言模型直接访问整个谷歌搜索索引,从而吸收全部信息,这体现了对 AI 技术未来潜力的极大想象力。
6、性能问题:符尧承认目前的 Gemini 1.5 在处理 1M 上下文时速度较慢,但他对提速持乐观态度,认为未来长上下文模型的速度将大大提升,最终可能达到与 RAG 相当的速度。

除了符尧,其他很多研究者也在 X 平台上发表了自己对于 RAG 前景的看法,比如 AI 博主 @elvis。

总体来看,他不认为长上下文模型能取代 RAG,理由包括:
1、特定数据类型的挑战:@elvis 提出了一种情景,即数据具有复杂结构、定期变化,并且具有重要的时间维度(例如代码编辑 / 更改和网络日志)。这种类型的数据可能与历史数据点相连,并且将来可能连接更多数据点。@elvis 认为,今天的长上下文语言模型单独无法处理依赖于此类数据的用例,因为这些数据对于 LLM 来说可能太复杂,且当前的最大上下文窗口对于此类数据来说并不可行。在处理此类数据时,最终可能需要某种巧妙的检索机制。
2、对动态信息的处理:今天的长上下文 LLM 在处理静态信息(如书籍、视频录像、PDF 等)方面表现出色,但在处理高度动态的信息和知识方面尚未经过实战测试。@elvis 认为,虽然我们将朝着解决一些挑战(如「lost in the middle」)以及处理更复杂的结构化和动态数据方面取得进展,但我们仍有很长的路要走。

3、@elvis 提出,为了解决这些类型的问题,可以将 RAG 和长上下文 LLM 结合起来,构建一个强大的系统,有效且高效地检索和分析关键的历史信息。他强调,即使这样,在许多情况下也可能不足够。特别是因为大量数据可能会迅速变化,基于 AI 的智能体增加了更多的复杂性。@elvis 认为,对于复杂的用例,很可能会结合这些想法,而不是通用或长上下文 LLM 取代一切。
4、对不同类型 LLM 的需求:@elvis 指出,不是所有数据都是静态的,很多数据都是动态的。在考虑这些应用时,需要记住大数据的三个 V:速度(velocity)、体量(volume)和多样性(variety)。@elvis 通过在搜索公司的工作经验学到了这一课。他认为,不同类型的 LLM 将帮助解决不同类型的问题,我们需要摒弃一个 LLM 将统治一切的想法。

@elvis 最后引用了 Oriol Vinyals(谷歌 DeepMind 的研究副总裁)的话,指出即使现在我们能够处理 100 万或更多 token 的上下文,RAG 的时代还远未结束。实际上,RAG 具有一些非常好的特性。这些特性不仅可以通过长上下文模型得到增强,而且长上下文模型也可以通过 RAG 得到增强。RAG 允许我们找到相关的信息,但是模型访问这些信息的方式可能由于数据压缩而变得过于受限。长上下文模型可以帮助弥补这一差距,这有点类似于现代 CPU 中 L1/L2 缓存和主内存是如何协同工作的。在这种协作模式下,缓存和主内存各自承担不同的角色,但又相互补充,从而提高了处理速度和效率。同样,RAG 和长上下文的结合使用,可以实现更灵活、更高效的信息检索和生成,充分利用各自的优势来处理复杂的数据和任务。

看来,「RAG 的时代是否即将终结」还没有定论。但很多人都表示,作为一个超长上下文窗口模型,Gemini 1.5 Pro 确实被低估了。@elvis 也给出了他的测试结果。

Gemini 1.5 Pro 初步测评报告
长文档分析能力
为了展示 Gemini 1.5 Pro 处理和分析文档的能力,@elvis 从一个非常基本的问题解答任务开始。他上传了一个 PDF 文件,并提出了一个简单的问题:这篇论文是关于什么的?
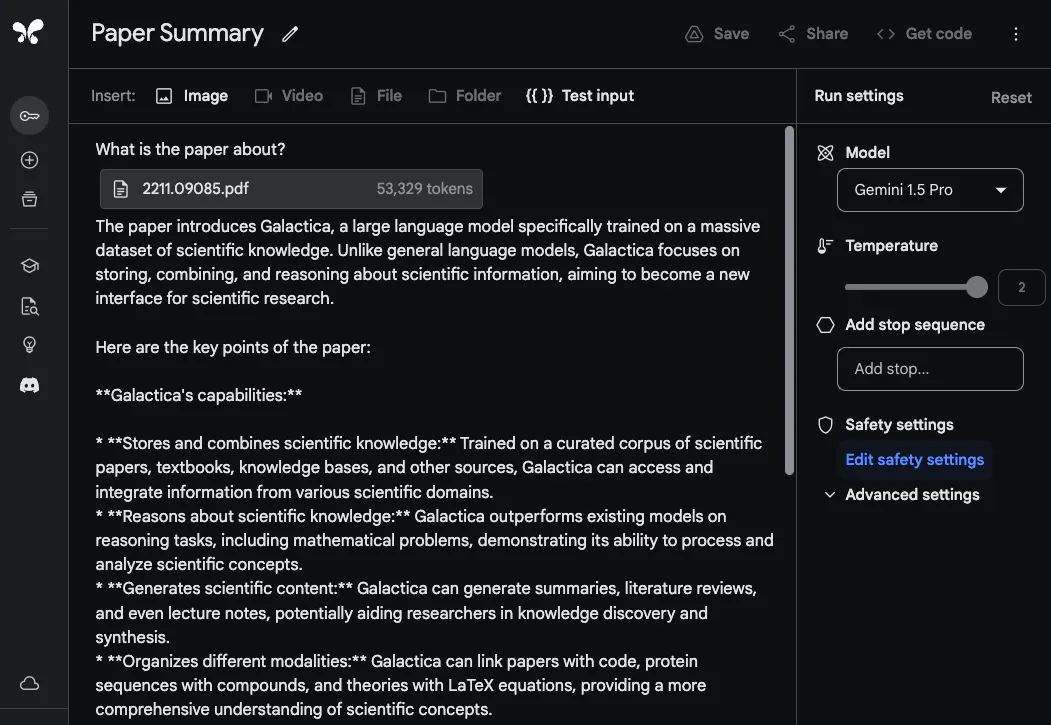
模型的回复准确而简洁,因为它提供了可接受的 Galactica 论文摘要。上面的示例使用的是 Google AI Studio 中的自由格式提示,但你也可以使用聊天格式与上传的 PDF 进行交互。如果你有很多问题想从所提供的文档中得到解答,这是一项非常有用的功能。

为了充分利用长上下文窗口,@elvis 接下来上传了两个 PDF 进行测试,并提出了一个跨越两个 PDF 的问题。

Gemini 1.5 Pro 给出的答复是合理的。有趣的是,从第一篇论文(关于 LLM 的综述论文)中提取的信息来自一个表格。「架构」信息看起来也是正确的。但是,「性能」部分并不属于这部分,因为第一篇论文中没有这部分内容。在这项任务中,重要的是要把提示「Please list the facts mentioned in the first paper about the large language model introduced in the second paper」放在最上面,并在论文上标注标签,如「Paper 1」和「Paper 2」 。本实验的另一个相关后续任务是通过上传一组论文和如何总结这些论文的说明来撰写相关工作。另一项有趣的任务是要求模型将较新的 LLM 论文写进综述。
视频理解
Gemini 1.5 Pro 从一开始就接受了多模态数据的训练。@elvis 用 Andrej Karpathy 最近的 LLM 讲座视频测试了一些提示:

他要求模型完成的第二项任务是提供一份简明扼要的讲座提纲(篇幅为一页)。回答如下(为简洁起见作了编辑):

Gemini 1.5 Pro 给出的摘要非常简洁,很好地概括了讲座内容和要点。
当具体细节非常重要时,请注意模型有时可能会产生「幻觉」,或由于各种原因检索到错误信息。例如,当向模型询问以下问题时:「What are the FLOPs reported for Llama 2 in the lecture?」,它的回答是「The lecture reports that training Llama 2 70B required approximately 1 trillion FLOPs」,这是不准确的。正确的回答应该是「~1e24 FLOPs」。技术报告中包含了许多例子,说明当被问及有关视频的具体问题时,这些长上下文模型会出现失误。
下一项任务是从视频中提取表格信息。测试结果表明,该模型能生成表格,其中一些细节正确,一些细节错误。例如,表格的列是正确的,但其中一行的标签是错误的(即 Concept Resolution 应该是 Coref Resolution)。测试者用其他表格和其他不同元素(如文本框)测试了其中一些提取任务,也发现了类似的不一致性。
技术报告中记录的一个有趣的例子是,模型能够根据特定场景或时间戳从视频中检索细节。在第一个例子中,测试者向模型询问某个部分是从哪里开始的。模型回答正确。
在下一个示例中,他要求模型解释幻灯片中的一个图表。该模型似乎很好地利用了所提供的信息来解释图表中的结果。

下面是相应幻灯片的快照:

@elvis 表示,他已经开始着手进行第二轮测试,感兴趣的同学可以去 X 平台上围观。
关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP