

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 141871关于域名注册需要知道的问题
- 118802浅谈融合CDN
- 61283简单网络管理协议SNMP
- 56544Multipoint BF
- 56145SBIDIOT IoT恶意
- 51376DDOS攻击的危害及防御方
- 45027企业该如何选择云服务器的配
- 41748影响云服务器价格的因素有哪
- 41429为什么选择海外云服务器?
- 311610Linux centos7
推荐阅读
- 11-061在数字化转型中,信息系统“好用”
- 11-172数字化转型的成功之道
- 12-113每个IT领导者都必须回答的八个变
- 12-184推动行业未来的八个数字化转型趋势
- 12-215初创企业和数字化转型:塑造202
- 12-256如何理性看待,中小企业数字化转型
- 01-047现代办公的数字化转型
- 01-098在什么情况下,数字化转型是成功的
- 01-159让数字化转型奏效的五大秘诀
- 01-24102024年五大数字化转型趋势
GPT-4、Gemini同时被曝重大缺陷,逻辑推理大翻车!DeepMind上交校友团队发现LLM严重降智
最近,谷歌DeepMind和斯坦福的研究人员发现:大模型在处理逻辑推理任务时,问题中信息呈现的顺序对模型的表现有着决定性的影响。

论文地址:https://arxiv.org/abs/2402.08939
具体来说,当信息按照逻辑上的自然顺序排列时,模型的表现会更好。这一发现不仅适用于一般的逻辑推理问题,对于数学问题也同样有效。
比如,如果某个证明任务的条件是:
1. 如果A,那么B;
2. 如果B,那么C;
3. A为真。
要求大模型证明C为真,如果条件按照1,2,3的顺序呈现,那么大模型的成功率会比2,1,3的条件呈现顺序高出很多。
所以,以后用大模型,言简意赅,符合逻辑地提出问题能让它性能更强。

上图展示了一个失败的案例,GPT-4,Gemini Pro,GPT-3.5在改变相关规则的顺序后都未能成功生成证明。

上图可以看出,对于当前主流的几个大模型,改变前提的叙述顺序都会导致性能大幅下降。
有趣的是,谷歌的新型模型Gemini Pro和OpenAI的GPT-3.5-Turbo,在下降趋势上几乎一样。
而且研究人员发现,如果进一步向上述逻辑推理任务中添加分散注意力的规则,打乱前提会导致更大的准确性下降。
实验中,研究人员通过将GSM8K测试集中的问题陈述顺序打乱,构建了GSM8K的变体——R-GSM测试集。
下图是其中一个例子,对于原本可以解决的问题,将前提顺序打乱之后(R-GSM),LLM就变得无能为力。

在R-GSM测试集中,几乎所有主流的LLM性能都出现了下降。

虽然人类在解决逻辑问题时,对前提顺序也会有偏好,但LLM「更容易」受到这种顺序效应的影响。
研究人员认为这可能是由于自回归模型训练目标和/或训练数据中的偏差造成的。
但如何应对这个问题仍然是一个有待进一步研究的挑战。
如果A是B,那么B也是A
众所周知,在逻辑推理中,改变前提条件的顺序并不会改变结论。
对于人类来说,在处理这类问题时也倾向于按照某种特定的顺序来排列前提,以便更好地推理。但这种偏好对解决问题的能力影响不大,尤其是在涉及到直接的逻辑推理(如果P,则Q、P;因此Q)时。
然而,对于大型语言模型来说,前提的顺序却极大地影响了它们的推理表现。
特别是,当前提的排列顺序与它们在正确证明中的出现顺序一致时,LLM的表现最好。
以刚才提出的简单任务为例,研究人员注意到两个现象:
1. 在提示中先提出「如果A则B」,然后是「如果B则C」,通常会比反过来的顺序有更高的准确率。
2. 当前提数量增多时,性能的差距会更加明显。
这种「乱序」的逻辑推理对人类来说很简单,但对语言模型而言却是一个重大的挑战。
研究发现,改变前提的顺序可以使模型的准确率下降超过30%。
而且有意思的是,不同的「乱序」对于不同的模型的影响也是完全不同的。
当前提的顺序与实际情况完全相反时,OpenAI的GPT模型表现得更好。这种方式使得模型能够通过从后向前的推理来进行推导。而PaLM 2-L在这种反向排序下的表现通常是最差的。
「逆序」评测基准R-GSM
为了进一步系统性地研究这个问题,研究人员在数学推理测试集GSM8K的基础之上开发了一个「乱序」测试集R-GSM。
具体来说,他们首先选择问题描述中至少有5个句子的GSM8K测试问题,然后过滤掉那些没法替换问题顺序的问题,例如遵循事件因果顺序的问题陈述系列。
对于剩下的每个问题,保持最后一句话不变,并用其他句子的不同顺序重写问题描述。允许对单词进行少量编辑,以确保问题描述的正确性。
而对GSM8K做这样的变化,原因是基于研究人员对于问题中前提顺序的看法和认知来进行调整的。
具体来说,研究人员将符合前向链式基本事实证明的顺序称为前向顺序,其中每个推导步骤中应用的规则在问题描述中依次呈现。
直观地说,按照前向顺序呈现前提对人类来说简化了问题,因为这允许人类在阅读前提的同时即时写出证明。
相反,如果前提排序更加随意,则会增加任务难度,因为在进行推导时,人类需要在每个推理步骤中重复查找前提。
受这种直觉的启发,他们根据不同前提顺序与前向顺序的Kendall tau距离??对其进行分类,归一化范围为[-1, 1]。
具体来说,?? = 1是前向阶次,将?? = -1的阶次表示为后向阶次,它是前向阶次的反向,并通过后向链与证明保持一致。
?? ≈ 0 表明问题描述中的前提顺序与证明之间没有很强的相关性。
为了深入研究 LLM 对不同前提顺序的偏好,除了正向(?? = 1)和反向(?? = -1)顺序外,他们还评估了模型在?? = 0.5、0和-0.5时的性能。
下图给出了 ?? = 1 和 0 的示例:

他们通过改变以下两个因素来衡量前提顺序效应:
- 证明所需的规则数量
规则越多,前提顺序效应就越明显。在他们的基准中,问题的规则数从4到12不等。
- 问题中出现的干扰规则(即对证明无用的规则)的数量
由于前提选择本身具有挑战性,而且LLM很容易被无关上下文分散注意力,因此分散注意力规则的存在也会使问题复杂化。
他们在问题变体中加入了0、5和10个干扰规则。
为每种数量的所需规则生成了200个问题。考虑到不同的前提顺序和干扰规则数量,每个问题包括15个变体,因此研究人员的基准中总共有27K个问题。
实验结果
研究人员对GPT-4-turbo、GPT-3.5-turbo、PaLM 2-L和Gemini Pro的前提排序效果进行了评估。
他们在温度为0的情况下执行贪婪解码,并在所有实验中应用零样本提示。
在R-GSM中,模型输入只包含问题描述,没有附加指令。对于逻辑推理,他们在提示中添加了一条指令,要求推导出每一步中使用的前提。
逻辑推理
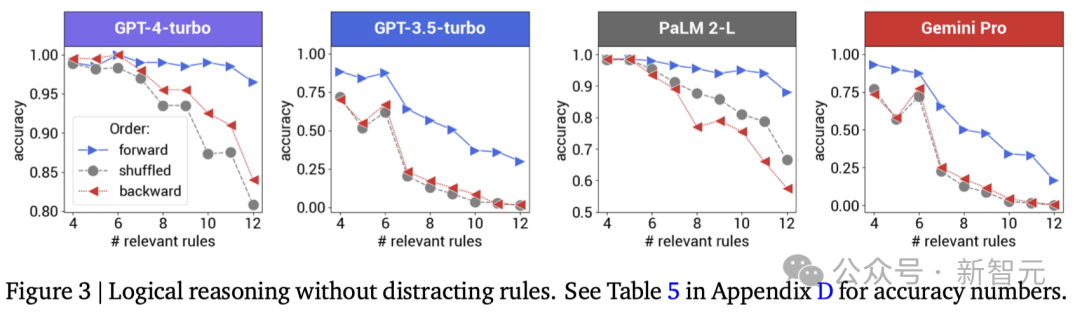
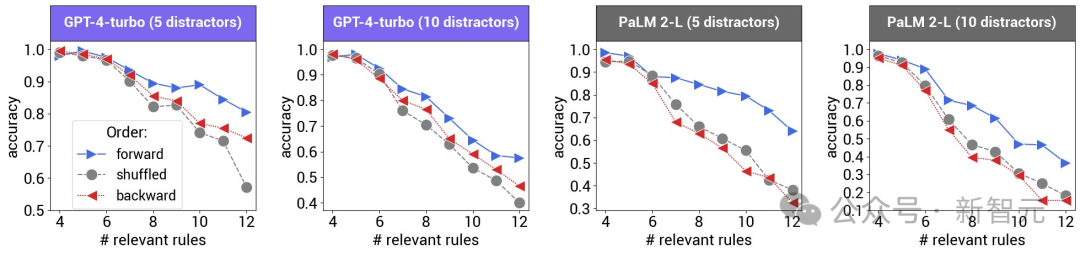
上图展示了在基本真理证明中包含不同数量相关规则的情况下的结果。
在这种情况下,问题不包含干扰规则,洗牌后的精确度是0.5、0 和-0.5时的结果。
在不同的LLM中,正向排序始终能达到最佳性能,这与人类的偏好一致。
当规则数量增加时,其他排序造成的性能下降会更加明显。
同时,推理能力较弱的模型对不同的前提顺序也更为敏感。
具体来说,GPT-4-turbo和PaLM 2-L的准确率下降最多为20%-30%,而对于Gemini-Pro和GPT-3.5-turbo,改变前置顺序会使准确率从65%以上下降到25%以下,准确率下降超过40%。
不同前提排序的细分
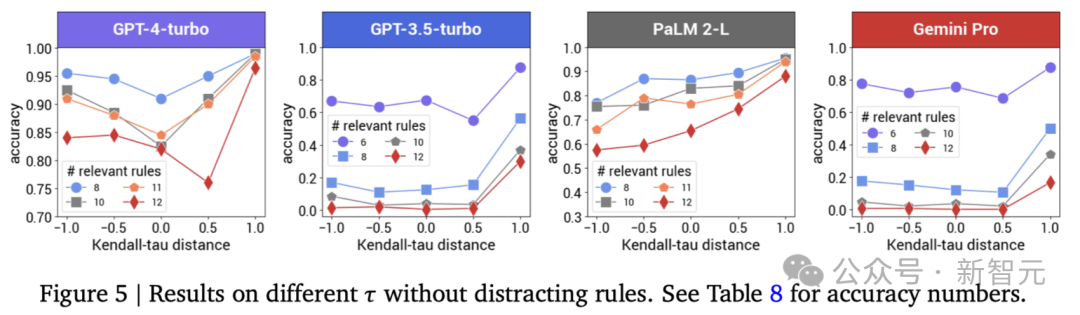
上图展示了对前提排序进行细粒度细分的结果,根据Kendall tau距离??对排序进行了分类。
有趣的是,虽然所有LLM最偏好前向排序,但它们对其他排序的偏好却不尽相同。
具体来说,GPT-4-turbo通常更喜欢后向阶,而且随着??的绝对值越小,整体性能也会下降。
这一观察结果与人类的推理模式也是一致的,因为后向链是另一种成熟的推理方法。
另一方面,PaLM 2-L在使用后向顺序时通常表现最差。
随着??的减小(即前提顺序与前向顺序的偏差增大),准确率也随之下降。Gemini Pro和GPT-3.5-turbo的偏好不太一致,但它们仍然比其他非正向前提顺序更倾向于使用后向顺序。
干扰规则的影响
研究人员评估了分心规则对GPT-4-turbo和PaLM 2-L的影响。

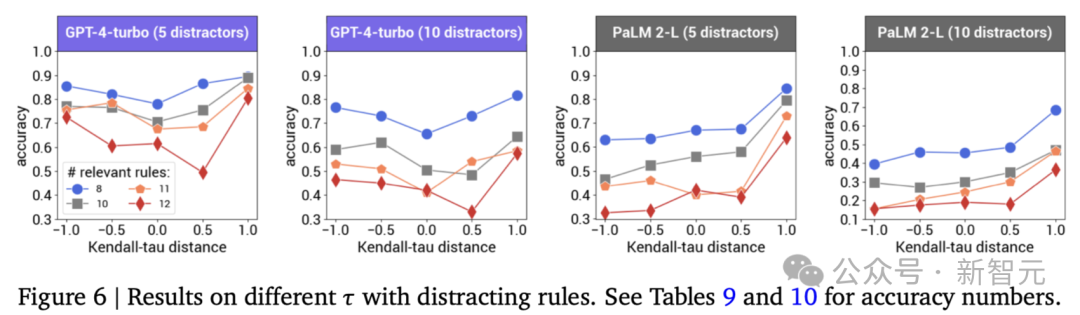
上图显示,添加干扰规则会进一步降低推理性能,并放大不同前提顺序的影响。
尽管如此,两个LLM的总体偏好仍然与没有干扰规则的情况相同。
具体地说,两个 LLM 在使用前向顺序时再次取得了最佳性能,GPT-4-turbo更喜欢使用后向顺序而不是其他非前向顺序,而PaLM 2-L的性能随着??越小而下降。

在上表中,研究人员列出了不同前提顺序下的预测误差细目。研究人员考虑了以下误差类别:
1. 错误反驳:LLM错误地声称结论无法证明;
2. 规则幻觉:LLM生成的规则在问题中并不存在;
3. 事实幻觉:LLM生成的事实在问题中并不存在,也无法证明。
研究人员发现,在所有LLM中,事实幻觉通常是最常见的错误模式,而且这种错误类型会随着??的减小而急剧增加。
主要原因是LLM倾向于按照问题中规则出现的先后顺序使用规则,因此当问题中的下一条规则尚未适用时,LLM可能仍然会幻觉出事实来完成证明步骤。
同时,研究人员观察到,在?? = -1的情况下,错误驳斥的比例通常低于 | ?? | < 1。
R-GSM对于数学推理的应用

上表显示了R-GSM的总体结果。可以看到,所有LLM在R-GSM上的性能都较低。
需要注意的是,GSM8K的原始问题并不一定是以最理想的方式编写的,因此有时人工重写会促进推理,使模型能够正确解决在原始问题上无法解决的重排序版本问题。
因此,在b中,对于每个LLM,也列出了模型在解决这些问题时对其原始描述的准确性。研究人员发现,所有LLM 在至少10%的重排序问题上都会失败,而在GPT-3.5-turbo中,这种性能下降超过了35%。
问题复杂度分解

上边两个图分别显示了不同推理步骤数和不同问题句子数的细分结果。
不难看出,在所有LLM中,需要更多推理步骤和包含更多句子的问题的证明准确率都会降低。
总体而言,GPT-4-turbo和Gemini Pro在推理步骤越多、问题越长的情况下,初始问题和重写问题的准确率差距就越大,而PaLM 2-L和GPT-3.5 turbo在推理步骤和问题长度不同的情况下,差距仍然相似。
为了进一步了解失败模式,他们针对每个LLM分析了那些原始问题可以正确解决而重新排序的问题却无法解决的错误案例,并在下表中对常见错误类型进行了分类。

与研究人员在逻辑推理实验中观察到的情况类似,R-GSM中的预测错误主要是由LLM按照数字在问题中出现的先后顺序盲目使用数字造成的。
具体来说,所有LLM最常见的错误情况就是容易忽略时间顺序。
预测失败的原因是问题的后半部分描述了一些早期事件。另一类错误发生在按顺序处理问题时没有指定某些量,从而引入未知变量进行计算。

以上图中的问题为例。在原问题中,每种动物的数量都可以根据其前一句话直接计算出来。
然而,在重新排序的问题中,沙鼠的数量无法根据前面的句子直接计算出来,因为到此为止,鱼的数量仍然是未知的,LLM必须先阅读剩下的句子并计算出鱼的数量。
然而,GPT-3.5-turbo的预测却使用上一步计算出的数字(即兔子的数量)来计算沙鼠的数量,从而导致错误。
这种失败模式在PaLM 2-L中不太常见,但在其他LLM的预测错误中仍占不可忽视的比例。
讨论
对于文章的给出的结论,有的网友想到了前提条件可能受时间方向的影响,从而导致不同的结果:
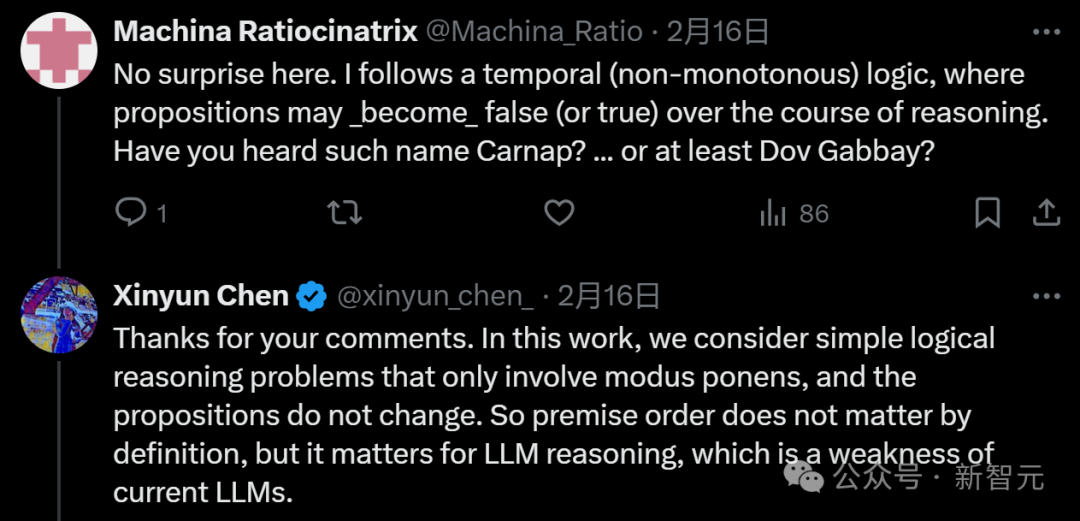
论文作者对此耐心回应道:「这里考虑的是只涉及模态的简单逻辑推理问题,命题不会改变。因此,根据定义,前提顺序并不重要,但对于LLM推理却很重要,而这正是当前LLM的一个弱点。」
一句话总结:虽然前提条件的顺序并不改变问题的本质,但会显著地影响大语言模型在推理任务上的表现。
研究人员经过全面的评估后发现,大语言模型在处理问题时,其表现与人类对前提顺序的偏好相似:
- 当前提的排序符合解题过程中的逻辑推理步骤时,模型的表现最佳;
- 当问题的推理过程要求模型反复阅读问题描述时,表现可能下降超过30%。
尽管人类在解决推理问题时也倾向于某种特定的前提顺序,但大语言模型对这种排序效应的敏感度要更高。这种影响的产生可能有多个原因,例如模型的自回归设计、训练目标和训练数据的组合等。
此外,研究人员还将研究扩展到数学推理领域,并提出了R-GSM基准测试,进一步实验性地证实了排序效应的存在。
作者介绍
Xinyun Chen(陈昕昀)

Xinyun Chen目前在Google DeepMind担任高级研究科学家,专注于大语言模型、代码自动生成以及人工智能安全领域的研究。
她于2022年在UC伯克利获得了计算机科学博士学位,并于2017年在上海交通大学ACM班取得了计算机科学学士学位,排名1/30。

此外,她还曾在Meta AI和日本国立情报学研究所进行过科研工作。
Ryan A. Chi

Ryan A. Chi目前在斯坦福大学攻读计算机科学专业的研究生学位,并辅修音乐。

他对于自然语言处理和人工智能在医疗领域的应用方面有着丰富的经验,曾带领斯坦福大学NLP团队「Chirpy Cardinal」在Alexa Prize社交机器人大挑战5中荣获第一名,并拿下25万美元的奖金。
此外,他曾在谷歌Deepmind、和英伟达工作过,并曾担任过斯坦福ACM和斯坦福交响乐团的主席,而且还是斯坦福扑克锦标赛的联合创始人。
关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP