

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 92641大模型×文本水印:清华、港
- 91552一文读懂如何基于 GenA
- 911732024 年,3 项技术将
- 90864AI在工业物联网(IIoT
- 90825利用人工智能增强网络安全防
- 90806人工智能和机器学习在物联网
- 90797GPT-4准确率最高飙升6
- 90568一句话让小姐姐为我换了N套
- 90549AI时代来了,专业摄影师会
- 9050102024年人工智能与数字孪
推荐阅读
- 01-241技术趋势:2024年的热点是什么
- 01-252网络安全在自动驾驶汽车中的作用
- 01-253OpenAI创始人想打造全球芯片
- 01-264强化学习和世界模型中的因果推断
- 01-265Mamba论文为什么没被ICLR
- 01-296让知识图谱成为大模型的伴侣
- 01-297从20亿数据中学习物理世界,基于
- 01-298谷歌云与Hugging Face
- 01-299人工智能和机器学习在物联网中的作
- 01-2910无需人工标注!LLM加持文本嵌入
LLM会写代码≠推理+规划!AAAI主席揭秘:代码数据质量太高|LeCun力赞
自从ChatGPT发布后,各种基于大模型的产品也快速融入了普通人的生活中,但即便非AI从业者在使用过几次后也可以发现,大模型经常会胡编乱造,生成错误的事实。
不过对于程序员来说,把GPT-4等大模型当作「代码辅助生成工具」来用的效果明显要比「事实检索工具」要好用很多,因为代码生成往往会涉及到复杂的逻辑分析等,所以也有人将这种推理(广义规划)能力归因于大型语言模型(LLM)的涌现。
学术界也一直在就「LLM能否推理」这个问题争论不休。

最近,计算机科学家、亚利桑那州立大学教授Subbarao Kambhampati(Rao)以「LLM真的能推理和规划吗?」(Can LLMs Really Reason & Plan?)为题,全面总结了语言模型在推理和规划方面的研究成果,其中也谈到了LLM的代码生成与推理能力的关联。

视频链接:https://www.youtube.com/watch?v=uTXXYi75QCU
PPT链接:https://www.dropbox.com/scl/fi/g3qm2zevcfkp73wik2bz2/SCAI-AI-Day-talk-Final-as-given.pdf
一句话总结:LLM的代码生成质量比英语(自然语言)生成质量更高,只能说明「在GitHub上进行近似检索」要比「通用Web上检索」更容易,而不能反映出任何潜在的推理能力。
造成这种差异的原因主要有两个:
1. 用于LLM训练的代码数据质量要比文本质量更高
2. 形式语言中「语法和语义的距离」比高度灵活的自然语言要低

图灵奖得主Yann LeCun也表示赞同:自回归LLM对编码非常有帮助,即便LLM真的不具备规划能力。
Rao教授是AAAI的主席,IJCAI的理事,以及Partnership on AI的创始董事会成员;他的主要研究方向为:

1. 面向人类的AI系统(Human-Aware AI Systems):可解释的人工智能交互。人工智能系统的规划和决策。人机组队。主动决策支持。可学习的规划模型和Model Lite规划。可解释的行为和解释。人为因素评估。
2. 自动规划(Automated Planning,AI):度量、时间、部分可访问和随机世界中的规划合成、启发式方法。规划的多目标优化。用富有表现力的动作推理。行程安排。加快学习以帮助规划者。约束满足与运筹学技术。规划在自动化制造和空间自主方面的应用。
3. 社交媒体分析与信息整合(Social Media Analysis & Information Integration):社交媒体平台上的人类行为分析。信息集成中用于查询优化和执行的自适应技术。源发现和源元数据学习。
代码生成≠推理+规划
已故的计算机科学家Drew McDermott曾经说过,规划只是一种语言的自动编程,每个原语都对应于可执行的操作(planning is just automatic programming on a language with primitives corresponding to executable actions)。
也就是说,广义上的规划可以写成程序,如果GPT-4或其他大模型可以正确地生成代码,那也就证明了LLM具有规划能力。
比如说去年5月,英伟达、加州理工等研究团队合作开发出了Voyager(旅行者)智能体,也是Minecraft(《我的世界》游戏)中首个基于LLM的具身、终身学习智能体(embodied lifelong learning agent),可以不断探索世界,获得各种技能,并在没有人为干预的情况下进行新的发现。

论文链接:https://arxiv.org/abs/2305.16291
Voyager的核心思想就是让LLM输出代码来执行任务,并且在模拟器中运行,包含三个关键组件:最大化探索(exploration)的自动课程(curriculum );用于存储和检索复杂行为的可执行代码的不断增长的技能库;新的迭代提示机制,包含环境反馈、执行错误和自我验证以改进程序。
Voyager通过黑盒查询与GPT-4进行交互,从而无需对模型参数进行微调。
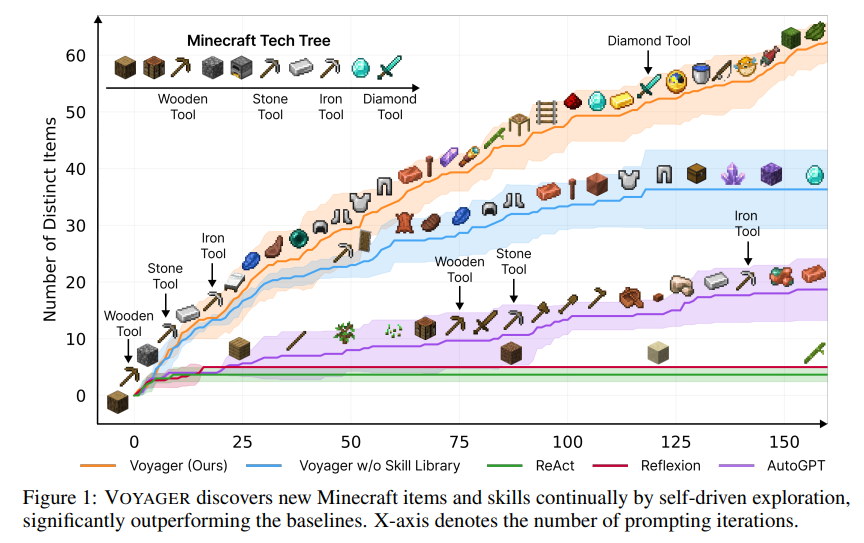
虽然还有其他类似Voyager的工作可以利用LLM以代码生成的方式完成规划,但这也并不能证明LLM就具有规划能力。
从原理上说,LLM本质上是一个近似检索器(approximate retrieval),能否成功规划取决于训练数据的质量。
在自然语言生成上,LLM需要吞噬海量数据,其中很多数据在事实基础或是价值体系上都存在很大分歧,比如地平论者和疫苗反对者也有自己的一套理论,可以写出令人信服的文章。
而在代码生成上,训练数据主要来自GitHub上的开源代码,其中大部分都是「有效数据」,而且软件工程师的价值体系对代码的质量影响微乎其微,这也可以解释为什么代码生成的质量要比文本补全的质量更高。
尽管如此,但代码生成的本质上仍然是近似检索,其正确性无法保证,所以在使用GitHub Copilot等辅助工具时,经常可以看到有人抱怨花了太长时间在生成代码的调试上,生成的代码往往看似运行良好,但背地里蕴藏bug
代码看起来能正常运行的部分原因可以归结为两个原因:
1. 系统中存在一个辅助工具(增量解释器),可以标记处明显的执行异常,可以让人类程序员在调试过程中注意到;
2. 语法上正确的代码段在语义上也可能是正确的,虽然无法完全保证,但语法正确是可执行的先决条件(对于自然语言来说也是如此)。
语言模型的自我验证
在少数情况下,例如上面提到的Voyager模型,其开发者声称:生成的代码质量已经足够好,可以直接在世界上运行,但仔细阅读就会发现,这种效果主要依赖于世界对规划模糊性的宽容。
某些论文中也会采用「LLM自我验证」(self-verify,self-critique自我批评)的方式,即在运行代码之前在目标场景中尝试执行验证一次,但同样,没有理由相信LLM具有自我验证的能力。
下面两篇论文就对模型的验证能力产生质疑。

论文链接:https://arxiv.org/abs/2310.12397
这篇论文系统地研究LLMs的迭代提示的有效性在图着色(Graph Coloring)的背景下(一个典型的NP完全推理问题),涉及到命题可满足性以及实际问题,如调度和分配;文中提出了一个原则性的实证研究GPT4在解决图着色实例或验证候选着色的正确性的性能。
在迭代模式中,研究人员要求模型来验证自己的答案,并用外部正确的推理机来验证所提出的解决方案。
结果发现:
1. LLMs在解决图着色实例方面很差;
2. 在验证解决方案方面并没有更好的表现-因此在迭代模式下,LLMs批评LLM生成的解决方案无效;
3. 批评的正确性和内容(LLMs本身和外部求解器)似乎在很大程度上与迭代提示的性能无关。
第二篇论文研究了大模型能否通过自我批评来改进规划。

论文链接:https://arxiv.org/abs/2310.08118
这篇论文的研究结果表明,自我批评似乎会降低规划生成性能,在使用GPT-4的情况下,无论是外部验证器还是自我验证器都在该系统中产生了非常多的误报,损害了系统的可靠性。
并且反馈信号为二元(正确、错误)和详细信息对规划生成的影响都很小,即LLM在自我批评、迭代规划任务框架下的有效性值得怀疑。
关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP