

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 92631大模型×文本水印:清华、港
- 91542一文读懂如何基于 GenA
- 911632024 年,3 项技术将
- 90864AI在工业物联网(IIoT
- 90825利用人工智能增强网络安全防
- 90796GPT-4准确率最高飙升6
- 90797人工智能和机器学习在物联网
- 90568一句话让小姐姐为我换了N套
- 90549AI时代来了,专业摄影师会
- 9049102024年人工智能与数字孪
推荐阅读
- 01-241技术趋势:2024年的热点是什么
- 01-252网络安全在自动驾驶汽车中的作用
- 01-253OpenAI创始人想打造全球芯片
- 01-264强化学习和世界模型中的因果推断
- 01-265Mamba论文为什么没被ICLR
- 01-296让知识图谱成为大模型的伴侣
- 01-297从20亿数据中学习物理世界,基于
- 01-298谷歌云与Hugging Face
- 01-299人工智能和机器学习在物联网中的作
- 01-2910无需人工标注!LLM加持文本嵌入
微软、国科大开启1Bit时代:大模型转三进制,速度快4倍能耗降至1/41
把大模型的权重统统改成三元表示,速度和效率的提升让人害怕。
今天凌晨,由微软、国科大等机构提交的一篇论文在 AI 圈里被人们争相转阅。该研究提出了一种 1-bit 大模型,实现效果让人只想说两个字:震惊。

如果该论文的方法可以广泛使用,这可能是生成式 AI 的新时代。
对此,已经有人在畅想 1-bit 大模型的适用场景,看起来很适合物联网,这在以前是不可想象的。

人们还发现,这个提升速度不是线性的 —— 而是,模型越大,这么做带来的提升就越大。

还有这种好事?看起来英伟达要掂量掂量了。
近年来,大语言模型(LLM)的参数规模和能力快速增长,既在广泛的自然语言处理任务中表现出了卓越的性能,也为部署带来了挑战,并引发人们担忧高能耗会对环境和经济造成影响。
因此,使用后训练(post-training)量化技术来创建低 bit 推理模型成为上述问题的解决方案。这类技术可以降低权重和激活函数的精度,显著降低 LLM 的内存和计算需求。目前的发展趋势是从 16 bits 转向更低的 bit,比如 4 bits。然而,虽然这类量化技术在 LLM 中广泛使用,但并不是最优的。
最近的工作提出了 1-bit 模型架构,比如 2023 年 10 月微软研究院、国科大和清华大学的研究者推出了 BitNet,在降低 LLM 成本的同时为保持模型性能提供了一个很有希望的技术方向。
BitNet 是第一个支持训练 1-bit 大语言模型的新型网络结构,具有强大的可扩展性和稳定性,能够显著减少大语言模型的训练和推理成本。与最先进的 8-bit 量化方法和全精度 Transformer 基线相比,BitNet 在大幅降低内存占用和计算能耗的同时,表现出了极具竞争力的性能。
此外,BitNet 拥有与全精度 Transformer 相似的扩展法则(Scaling Law),在保持效率和性能优势的同时,还可以更加高效地将其能力扩展到更大的语言模型上, 从而让 1 比特大语言模型(1-bit LLM)成为可能。
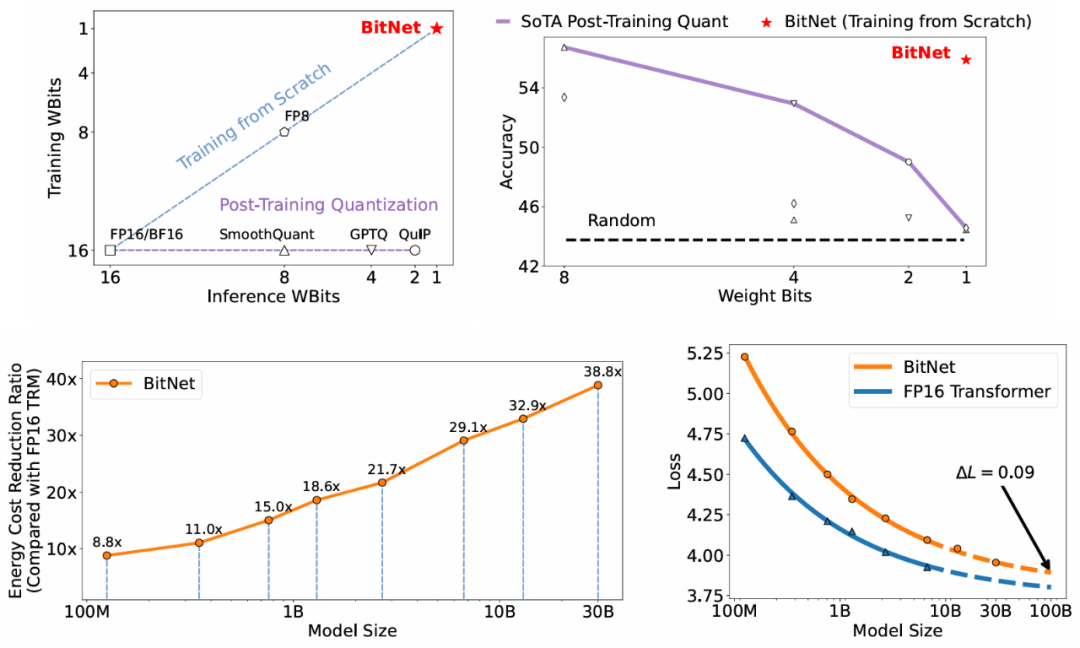
BitNet 从头训练的 1-bit Transformers 在能效方面取得了有竞争力的结果。来源:https://arxiv.org/pdf/2310.11453.pdf
如今,微软研究院、国科大同一团队(作者部分变化)的研究者推出了 BitNet 的重要 1-bit 变体,即 BitNet b1.58,其中每个参数都是三元并取值为 {-1, 0, 1}。他们在原来的 1-bit 上添加了一个附加值 0,得到二进制系统中的 1.58 bits。
BitNet b1.58 继承了原始 1-bit BitNet 的所有优点,包括新的计算范式,使得矩阵乘法几乎不需要乘法运算,并可以进行高度优化。同时,BitNet b1.58 具有与原始 1-bit BitNet 相同的能耗,相较于 FP16 LLM 基线在内存消耗、吞吐量和延迟方面更加高效。

论文地址:https://arxiv.org/pdf/2402.17764.pdf
论文标题:The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
此外,BitNet b1.58 还具有两个额外优势。其一是建模能力更强,这是由于它明确支持了特征过滤,在模型权重中包含了 0 值,显著提升了 1-bit LLM 的性能。其二实验结果表明,当使用相同配置(比如模型大小、训练 token 数)时,从 3B 参数规模开始, BitNet b1.58 在困惑度和最终任务的性能方面媲美全精度(FP16)基线方法。
如下图 1 所示,BitNet b1.58 为降低 LLM 推理成本(延迟、吞吐量和能耗)并保持模型性能提供了一个帕累托(Pareto)解决方案。

BitNet b1.58 介绍
BitNet b1.58 基于 BitNet 架构,并且用 BitLinear 替代 nn.Linear 的 Transformer。BitNet b1.58 是从头开始训练的,具有 1.58 bit 权重和 8 bit 激活。与原始 BitNet 架构相比,它引入了一些修改,总结为如下:

用于激活的量化函数与 BitNet 中的实现相同,只是该研究没有将非线性函数之前的激活缩放到 [0, Q_b] 范围。相反,每个 token 的激活范围为 [?Q_b, Q_b],从而消除零点量化。这样做对于实现和系统级优化更加方便和简单,同时对实验中的性能产生的影响可以忽略不计。
与 LLaMA 类似的组件。LLaMA 架构已成为开源大语言模型的基本标准。为了拥抱开源社区,该研究设计的 BitNet b1.58 采用了类似 LLaMA 的组件。具体来说,它使用了 RMSNorm、SwiGLU、旋转嵌入,并且移除了所有偏置。通过这种方式,BitNet b1.58 可以很容易的集成到流行的开源软件中(例如,Huggingface、vLLM 和 llama.cpp2)。
实验及结果
该研究将 BitNet b1.58 与此前该研究重现的各种大小的 FP16 LLaMA LLM 进行了比较,并评估了模型在一系列语言任务上的零样本性能。除此之外,实验还比较了 LLaMA LLM 和 BitNet b1.58 运行时的 GPU 内存消耗和延迟。
表 1 总结了 BitNet b1.58 和 LLaMA LLM 的困惑度和成本:在困惑度方面,当模型大小为 3B 时,BitNet b1.58 开始与全精度 LLaMA LLM 匹配,同时速度提高了 2.71 倍,使用的 GPU 内存减少了 3.55 倍。特别是,当模型大小为 3.9B 时,BitNet b1.58 的速度是 LLaMA LLM 3B 的 2.4 倍,消耗的内存减少了 3.32 倍,但性能显著优于 LLaMA LLM 3B。

表 2 结果表明,随着模型尺寸的增加,BitNet b1.58 和 LLaMA LLM 之间的性能差距缩小。更重要的是,BitNet b1.58 可以匹配从 3B 大小开始的全精度基线的性能。与困惑度观察类似,最终任务( end-task)结果表明 BitNet b1.58 3.9B 优于 LLaMA LLM 3B,具有更低的内存和延迟成本。
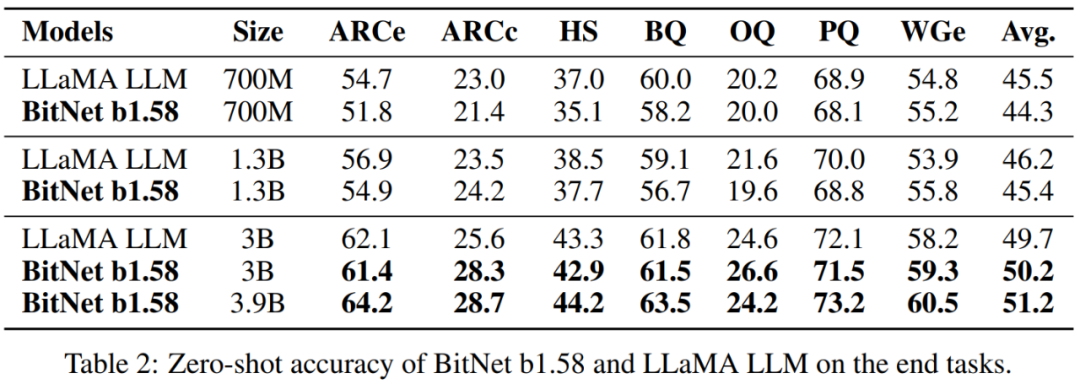
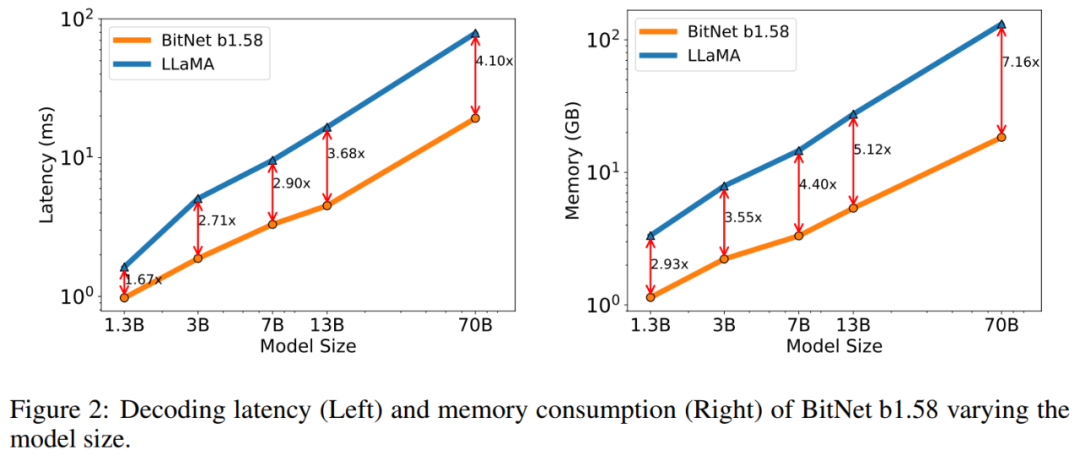
内存和延迟:该研究进一步将模型大小扩展到 7B、13B 和 70B 并评估成本。图 2 显示了延迟和内存的趋势,随着模型大小的增加,增长速度(speed-up)也在增加。特别是,BitNet b1.58 70B 比 LLaMA LLM 基线快 4.1 倍。这是因为 nn.Linear 的时间成本随着模型大小的增加而增加,内存消耗同样遵循类似的趋势。延迟和内存都是用 2 位核测量的,因此仍有优化空间以进一步降低成本。
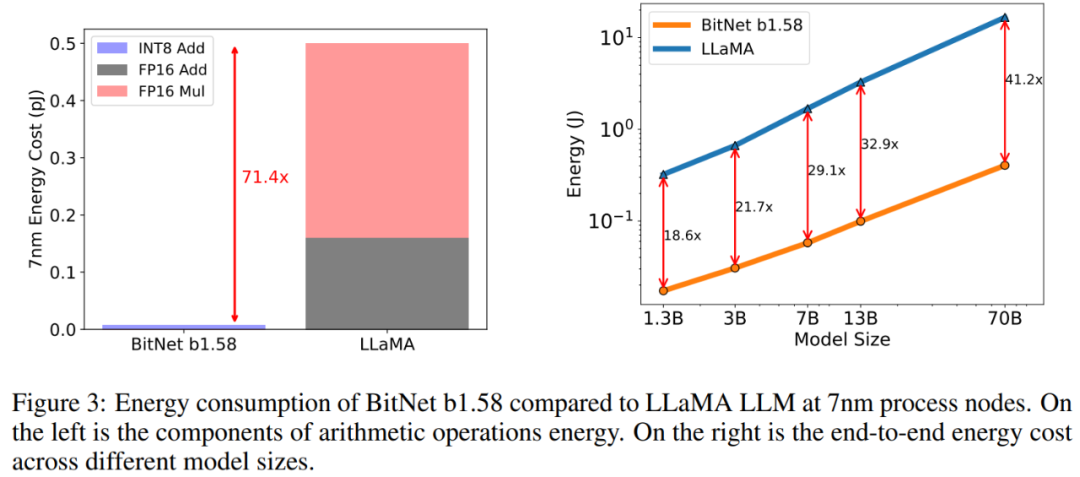
能耗。该研究还对 BitNet b1.58 和 LLaMA LLM 的算术运算能耗进行了评估,主要关注矩阵乘法。图 3 说明了能耗成本的构成。BitNet b1.58 的大部分是 INT8 加法计算,而 LLaMA LLM 则由 FP16 加法和 FP16 乘法组成。根据 [Hor14,ZZL22] 中的能量模型,BitNet b1.58 在 7nm 芯片上的矩阵乘法运算能耗节省了 71.4 倍。
该研究进一步报告了能够处理 512 个 token 模型的端到端能耗成本。结果表明,随着模型规模的扩大,与 FP16 LLaMA LLM 基线相比,BitNet b1.58 在能耗方面变得越来越高效。这是因为 nn.Linear 的百分比随着模型大小的增加而增长,而对于较大的模型,其他组件的成本较小。
吞吐量。该研究比较了 BitNet b1.58 和 LLaMA LLM 在 70B 参数体量上在两个 80GB A100 卡上的吞吐量,使用 pipeline 并行性 [HCB+19],以便 LLaMA LLM 70B 可以在设备上运行。实验增加了 batch size,直到达到 GPU 内存限制,序列长度为 512。表 3 显示 BitNet b1.58 70B 最多可以支持 LLaMA LLM batch size 的 11 倍,从而将吞吐量提高 8.9 倍。

更多技术细节请查看原论文。
关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP